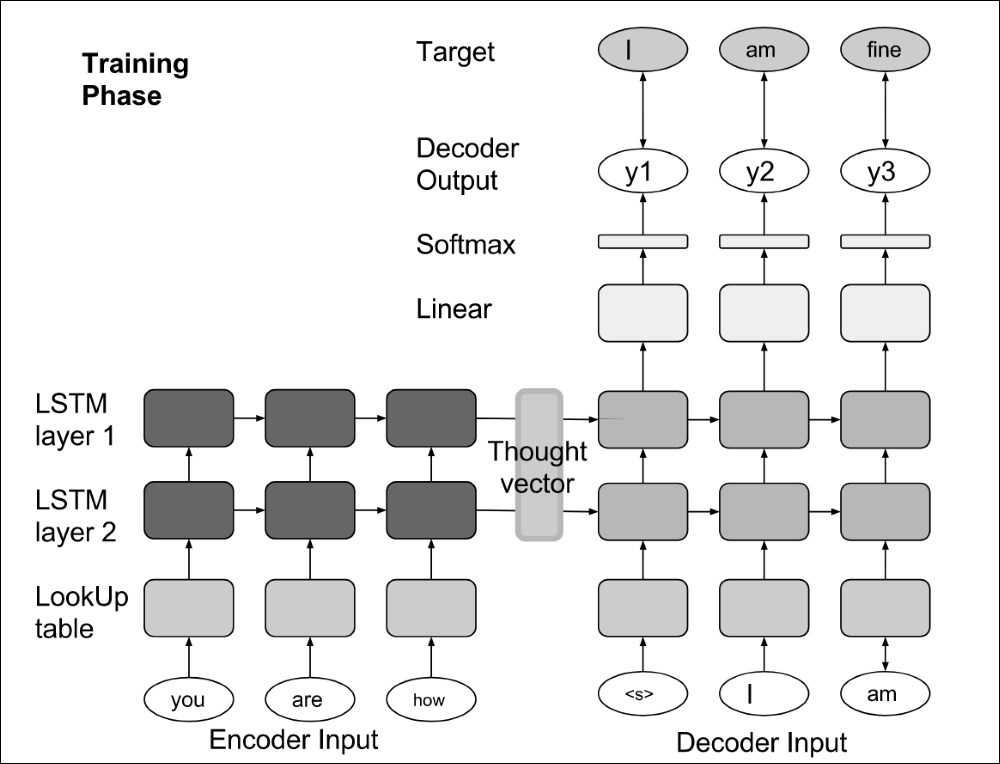
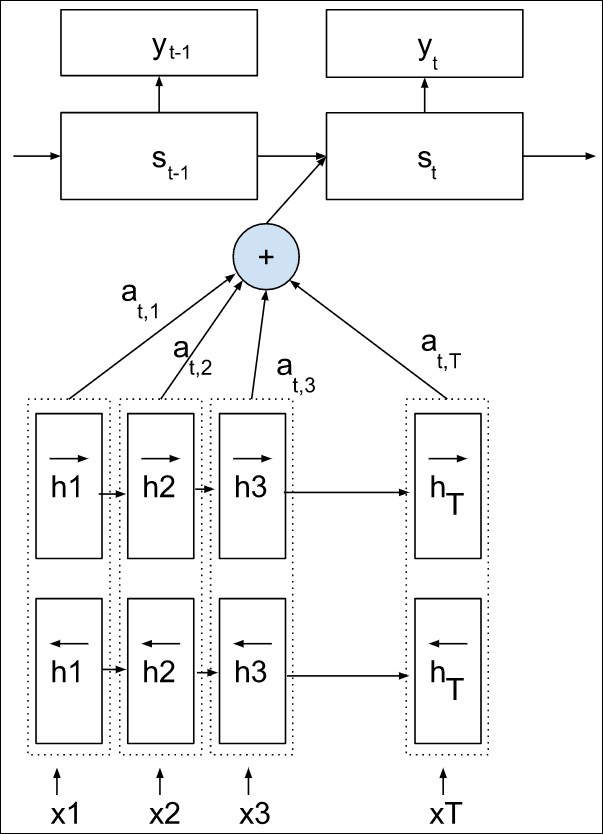
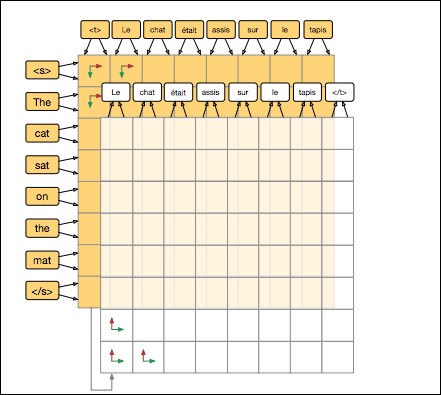
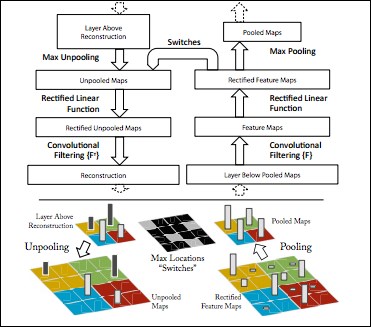
Encoding-decoding techniques occur when inputs and outputs belong to the same space. For example, image segmentation consists of transforming an input image into a new image, the segmentation mask; translation consists of transforming a character sequence into a new character sequence; and question-answering consists of replying to a sequence of words with a new sequence of words.
To address these challenges, encoding-decoding networks are networks composed of two symmetric parts: an encoding network and a decoding network. The encoder network encodes the input data into a vector, which will be used by the decoder network to produce an output, such as a translation, an answer to the input question, an explanation, or an annotation of an input sentence or an input image.
An encoder network is usually composed of the first layers of a network of the type of the ones presented in the previous chapters, without the last layers...