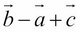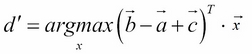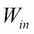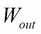In the previous chapter, inputs to neural nets were images, that is, vectors of continuous numeric values, the natural language for neural nets. But for many other machine learning fields, inputs may be categorical and discrete.
In this chapter, we'll present a technique known as embedding, which learns to transform discrete input signals into vectors. Such a representation of inputs is an important first step for compatibility with the rest of neural net processing.
Such embedding techniques will be illustrated with an example of natural language texts, which are composed of words belonging to a finite vocabulary.
We will present the different aspects of embedding:
The principles of embedding
The different types of word embedding
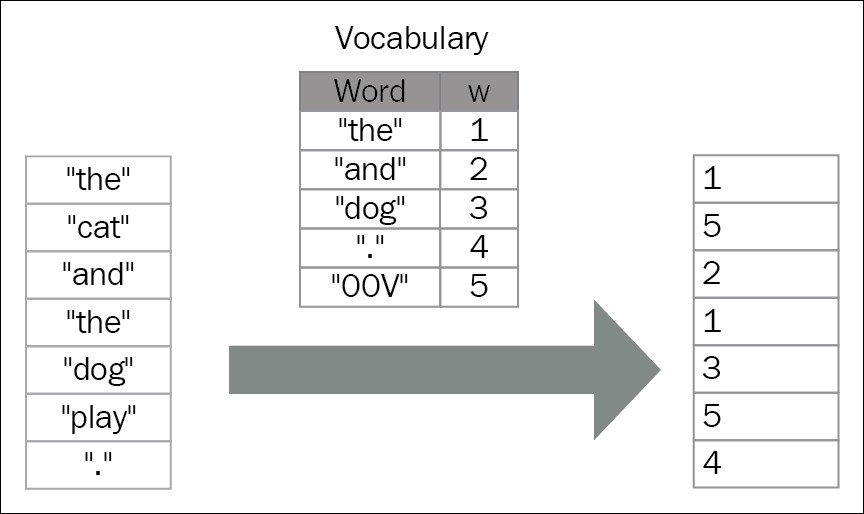
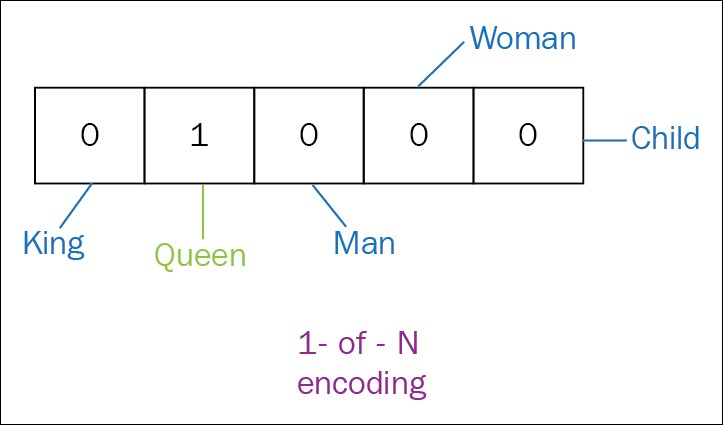
One hot encoding versus index encoding
Building a network to translate text into vectors
Training and discovering the properties of embedding spaces
Saving and loading the parameters of a model
Dimensionality reduction for visualization...