In the previous chapter, you learned how to represent a discrete input into a vector so that neural nets have the power to understand discrete inputs as well as continuous ones.
Many real-world applications involve variable-length inputs, such as connected objects and automation (sort of Kalman filters, much more evolved); natural language processing (understanding, translation, text generation, and image annotation); human behavior reproduction (text handwriting generation and chat bots); and reinforcement learning.
Previous networks, named feedforward networks, are able to classify inputs of fixed dimensions only. To extend their power to variable-length inputs, a new category of networks has been designed: the recurrent neural networks (RNN) that are well suited for machine learning tasks on variable-length inputs or sequences.
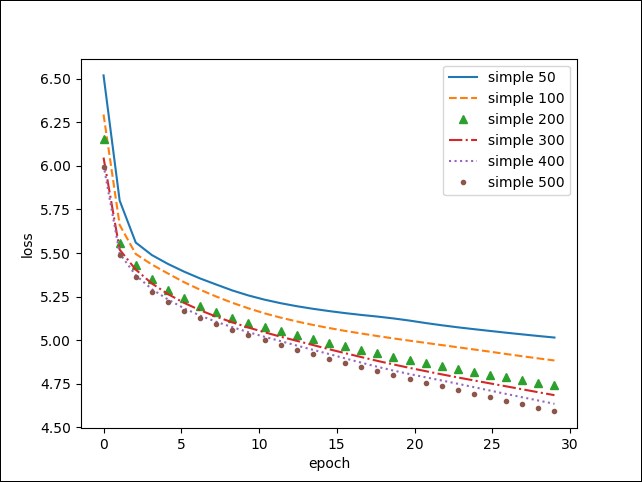
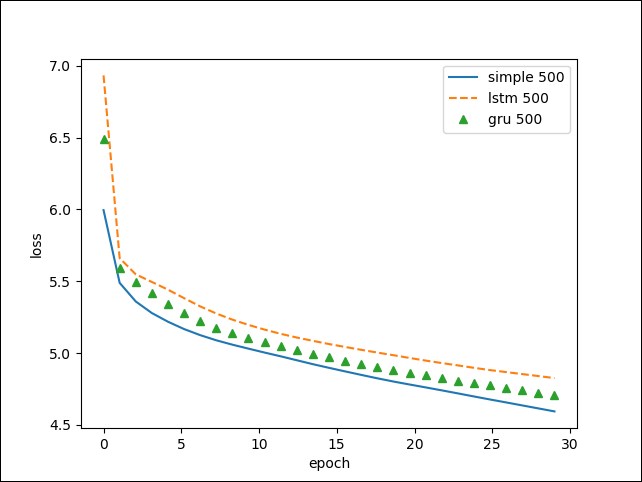
Three well-known recurrent neural nets (simple RNN, GRU, and LSTM) are presented for the example of text generation...