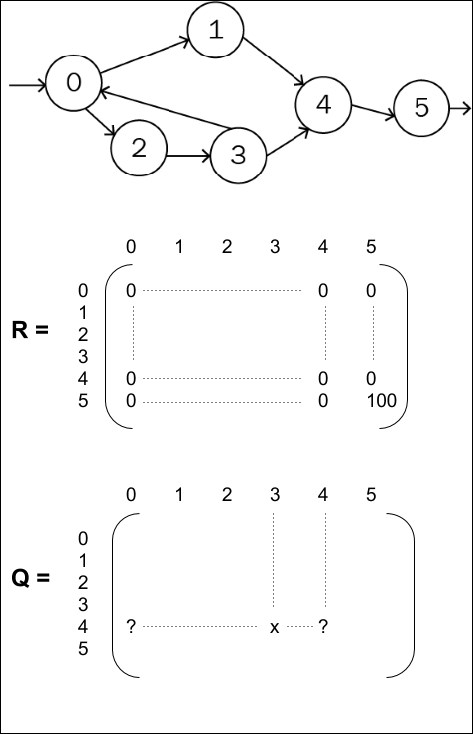
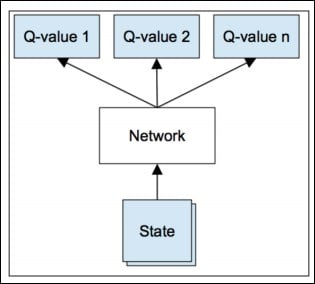
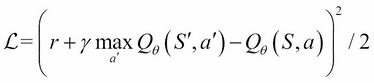Supervised and unsupervised learning describe the presence or the absence of labels or targets during training. A more natural learning environment for an agent is to receive rewards when the correct decision has been taken. This reward, such as playing correctly tennis for example, may be attributed in a complex environment, and the result of multiple actions, delayed or cumulative.
In order to optimize the reward from the environment for an artificial agent, the Reinforcement Learning (RL) field has seen the emergence of many algorithms, such as Q-learning, or Monte Carlo Tree Search, and with the advent of deep learning, these algorithms have been revised into new methods, such as deep-Q-networks, policy networks, value networks, and policy gradients.
We'll begin with a presentation of the reinforcement learning frame, and its potential application to virtual environments. Then, we'll develop its algorithms and their integration...