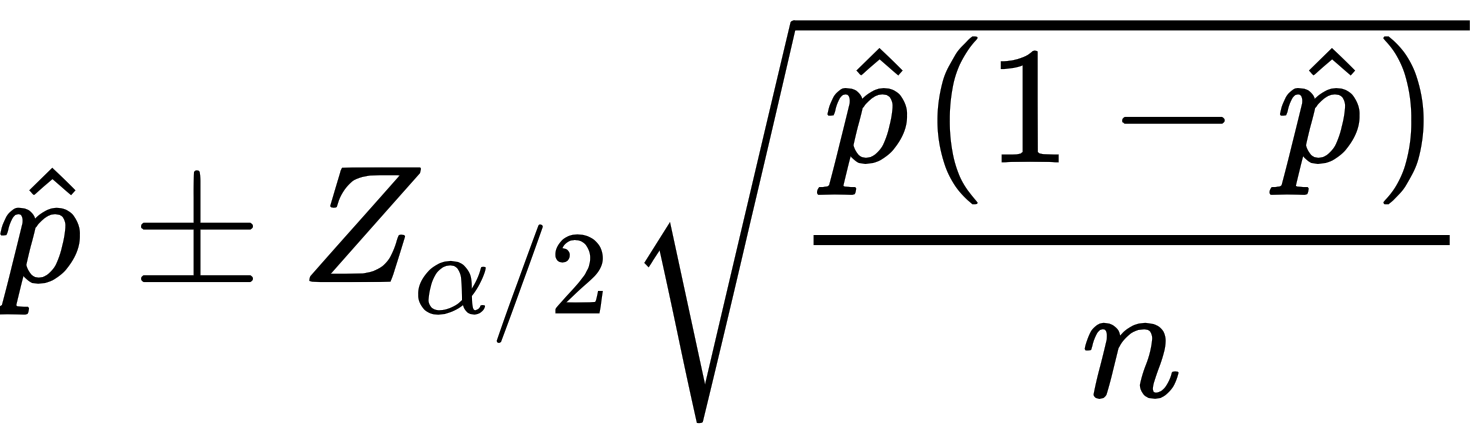In this recipe, we have the number of people in a town, and whether they vote for Candidate A or Candidate B – these are flagged by 1s and 0s. We want to study the variability of several sample sizes, and ultimately we want to define which sample size is appropriate. Intuition would suggest that the error decreases nonlinearly as we increase the sample size: when the sample size is small, the error should decrease slowly as we increase the sample size. On the other hand, it should decrease quickly when the sample is large.
- Import the libraries:
library(dplyr)
library(ggplot2)
- Load the dataset:
voters_data = read.csv("./voters_.csv")
- Take 1,000 samples of size 10 and calculate the proportion of people voting for Candidate A:
proportions_10sample = c()
for (q in 2:1000){
sample_data = mean(sample(voters_data$Vote,10,replace = FALSE))
proportions_10sample = c(proportions_10sample,sample_data)
}
- Take 1,000 samples of size 50 and calculate the proportion of people voting for Candidate A:
proportions_50sample = c()
for (q in 2:1000){
sample_data = mean(sample(voters_data$Vote,50,replace = FALSE))
proportions_50sample = c(proportions_50sample,sample_data)
}
- Take 1,000 samples of size 100 and calculate the proportion of people voting for Candidate A:
proportions_100sample = c()
for (q in 2:1000){
sample_data = mean(sample(voters_data$Vote,100,replace = FALSE))
proportions_100sample = c(proportions_100sample,sample_data)
}
- Take 1,000 samples of size 500 and calculate the proportion of people voting for Candidate A:
proportions_500sample = c()
for (q in 2:1000){
sample_data = mean(sample(voters_data$Vote,500,replace = FALSE))
proportions_500sample = c(proportions_500sample,sample_data)
}
- We combine all the DataFrames, and calculate the 2.5% and 97.5% quantiles:
joined_data50 = data.frame("sample_size"=50,"mean"=mean(proportions_50sample), "q2.5"=quantile(proportions_50sample,0.025),"q97.5"=quantile(proportions_50sample,0.975))
joined_data10 = data.frame("sample_size"=10,"mean"=mean(proportions_10sample), "q2.5"=quantile(proportions_10sample,0.025),"q97.5"=quantile(proportions_10sample,0.975))
joined_data100 = data.frame("sample_size"=100,"mean"=mean(proportions_100sample), "q2.5"=quantile(proportions_100sample,0.025),"q97.5"=quantile(proportions_100sample,0.975))
joined_data500 = data.frame("sample_size"=500,"mean"=mean(proportions_500sample), "q2.5"=quantile(proportions_500sample,0.025),"q97.5"=quantile(proportions_500sample,0.975))
- After combining them, we use the Gaussian approximation to get the 2.5% and 97.5% quantiles. Note that we use 1.96, which is the associated 97.5% quantile (and -1.96 for the associated 2.5% quantile, due to the symmetry of the Gaussian distribution):
data_sim = rbind(joined_data10,joined_data50,joined_data100,joined_data500)
data_sim = data_sim %>% mutate(Nq2.5 = mean - 1.96*sqrt(mean*(1-mean)/sample_size),N97.5 = mean + 1.96*sqrt(mean*(1-mean)/sample_size))
data_sim$sample_size = as.factor(data_sim$sample_size)
- Plot the previous DataFrame using the ggplot function:
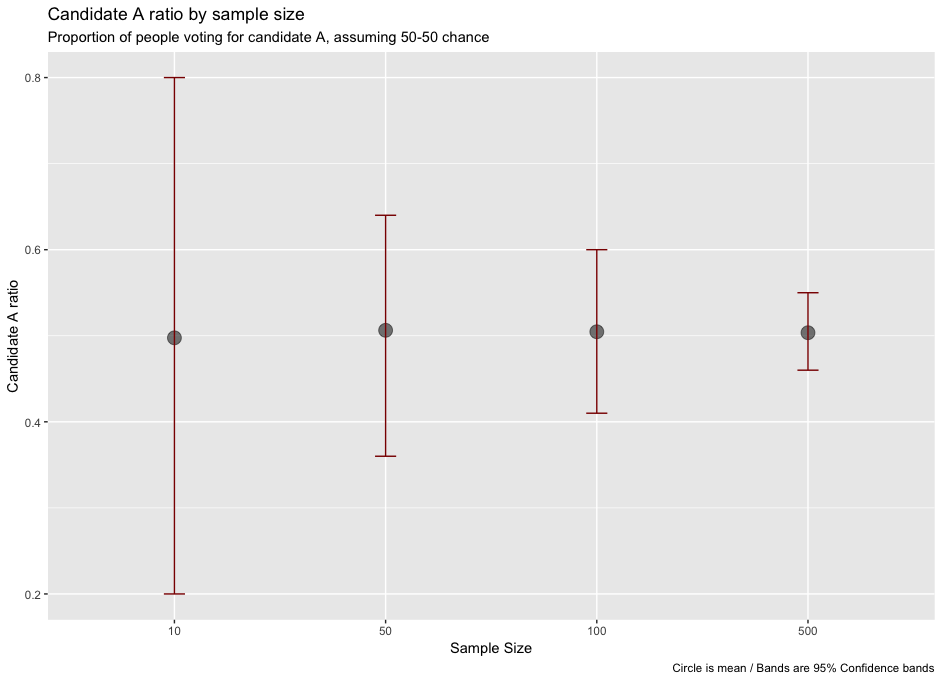
ggplot(data_sim, aes(x=sample_size, y=mean, group=1)) +
geom_point(aes(size=2), alpha=0.52) + theme(legend.position="none") +
geom_errorbar(width=.1, aes(ymin=q2.5, ymax=q97.5), colour="darkred") + labs(x="Sample Size",y= "Candidate A ratio", title="Candidate A ratio by sample size", subtitle="Proportion of people voting for candidate A, assuming 50-50 chance", caption="Circle is mean / Bands are 95% Confidence bands")
This provides the following result:



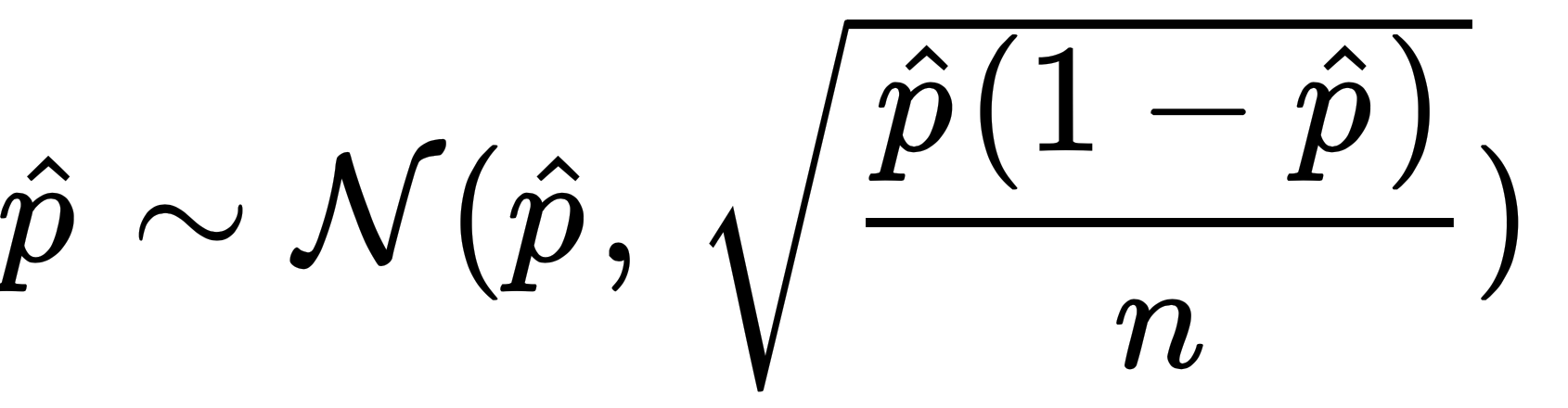
 in order to achieve an interval of
in order to achieve an interval of 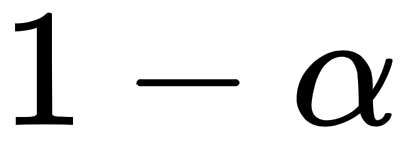 , as implemented in the following formula:
, as implemented in the following formula: