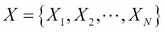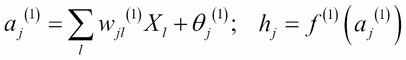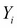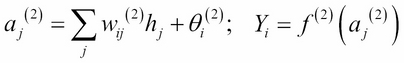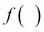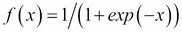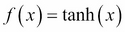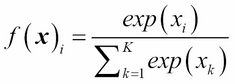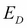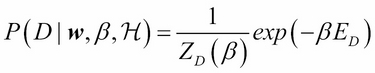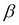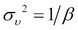As the name suggests, artificial neural networks are statistical models built taking inspirations from the architecture and cognitive capabilities of biological brains. Neural network models typically have a layered architecture consisting of a large number of neurons in each layer, and neurons between different layers are connected. The first layer is called input layer, the last layer is called output layer, and the rest of the layers in the middle are called hidden layers. Each neuron has a state that is determined by a nonlinear function of the state of all neurons connected to it. Each connection has a weight that is determined from the training data containing a set of input and output pairs. This kind of layered architecture of neurons and their connections is present in the neocortex region of human brain and is considered to be responsible for higher functions such as sensory perception and language understanding.
The first computational model...