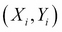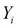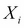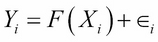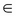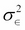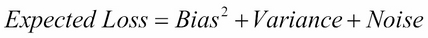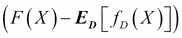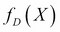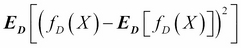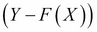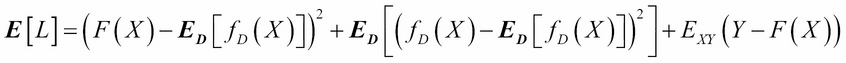Now that we have learned about Bayesian inference and R, it is time to use both for machine learning. In this chapter, we will give an overview of different machine learning techniques and discuss each of them in detail in subsequent chapters. Machine learning is a field at the intersection of computer science and statistics, and a subbranch of artificial intelligence or AI. The name essentially comes from the early works in AI where researchers were trying to develop learning machines that automatically learned the relationship between input and output variables from data alone. Once a machine is trained on a dataset for a given problem, it can be used as a black box to predict values of output variables for new values of input variables.
It is useful to set this learning process of a machine in a mathematical framework. Let X and Y be two random variables such that we seek a learning machine that learns the relationship between these...