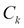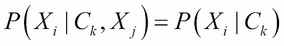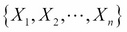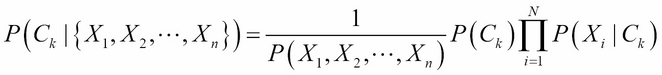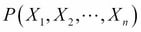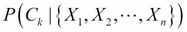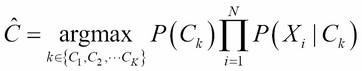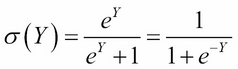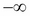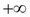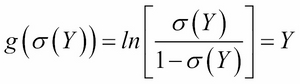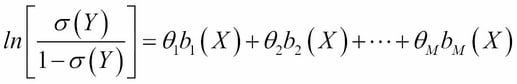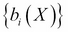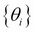We introduced the classification machine learning task in Chapter 4, Machine Learning Using Bayesian Inference, and said that the objective of classification is to assign a data record into one of the predetermined classes. Classification is one of the most studied machine learning tasks and there are several well-established state of the art methods for it. These include logistic regression models, support vector machines, random forest models, and neural network models. With sufficient labeled training data, these models can achieve accuracies above 95% in many practical problems.
Then, the obvious question is, why would you need to use Bayesian methods for classification? There are two answers to this question. One is that often it is difficult to get a large amount of labeled data for training. When there are hundreds or thousands of features in a given problem, one often needs a large amount of training data for these supervised methods to avoid...