

The machine learning models that we have discussed so far in the previous two chapters share one common characteristic: they require training data containing ground truth. This implies a dataset containing true values of the predicate or dependent variable that is often manually labeled. Such machine learning where the algorithm is trained using labeled data is called supervised learning. This type of machine learning gives a very good performance in terms of accuracy of prediction. It is, in fact, the de facto method used in most industrial systems using machine learning. However, the drawback of this method is that, when one wants to train a model with large datasets, it would be difficult to get the labeled data. This is particularly relevant in the era of Big Data as a lot of data is available for organizations from various logs, transactions, and interactions with consumers; organizations want to gain insight from this data and make...

In general, a mixture model corresponds to representing data using a mixture of probability distributions. The most common mixture model is of the following type:
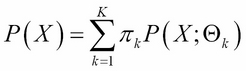
Here, 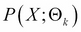 is a probability distribution of X with parameters
is a probability distribution of X with parameters 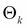 , and
, and 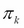 represents the weight for the kth component in the mixture, such that
represents the weight for the kth component in the mixture, such that 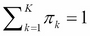 . If the underlying probability distribution is a normal (Gaussian) distribution, then the mixture model is called a
Gaussian mixture model (GMM). The mathematical representation of GMM, therefore, is given by:
. If the underlying probability distribution is a normal (Gaussian) distribution, then the mixture model is called a
Gaussian mixture model (GMM). The mathematical representation of GMM, therefore, is given by:
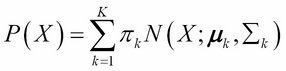
Here, we have used the same notation, as in previous chapters, where X stands for an N-dimensional data vector 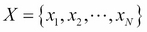 representing each observation and there are M such observations in the dataset.
representing each observation and there are M such observations in the dataset.
A mixture model such as this is suitable for clustering when the clusters have overlaps. One of the applications of GMM is in computer vision. If one wants to track moving objects in a video, it is useful to subtract the background image. This is called background subtraction or...
We have seen the supervised learning (classification) of text documents in Chapter 6, Bayesian Classification Models, using the Naïve Bayes model. Often, a large text document, such as a news article or a short story, can contain different topics as subsections. It is useful to model such intra-document statistical correlations for the purpose of classification, summarization, compression, and so on. The Gaussian mixture model learned in the previous section is more applicable for numerical data, such as images, and not for documents. This is because words in documents seldom follow normal distribution. A more appropriate choice would be multinomial distribution.
A powerful extension of mixture models to documents is the work of T. Hofmann on Probabilistic Semantic Indexing (reference 6 in the References section of this chapter) and that of David Blei, et. al. on Latent Dirichlet allocation (reference 7 in the References section of this chapter). In...
There are mainly two packages in R that can be used for performing LDA on documents. One is the topicmodels package developed by Bettina Grün and Kurt Hornik and the second one is lda developed by Jonathan Chang. Here, we describe both these packages.
The topicmodels package is an interface to the C and C++ codes developed by the authors of the papers on LDA and
Correlated Topic Models (CTM) (references 7, 8, and 9 in the References section of this chapter). The main function LDA in this package is used to fit LDA models. It can be called by:
>LDA(X,K,method = "Gibbs",control = NULL,model = NULL,...)
Here, X is a document-term matrix that can be generated using the tm package and K is the number of topics. The method is the method to be used for fitting. There are two methods that are supported: Gibbs and VEM.
Let's do a small example of building LDA models using this package. The dataset used is the Reuter_50_50 dataset from the UCI Machine Learning...
For the Reuter_50_50 dataset, fit the LDA model using the
lda.collapsed.gibbs.samplerfunction in the lda package and compare performance with that of the topicmodels package. Note that you need to convert the document-term matrix to lda format using thedtm2ldaformat( )function in the topicmodels package in order to use the lda package.
Bouwmans, T., El Baf F., and "Vachon B. Background Modeling Using Mixture of Gaussians for Foreground Detection – A Survey" (PDF). Recent Patents on Computer Science 1: 219-237. 2008
Bishop C.M. Pattern Recognition and Machine Learning. Springer. 2006
Biecek P., Szczurek E., Tiuryn J., and Vingron M. "The R Package bgmm: Mixture Modeling with Uncertain Knowledge". Journal of Statistical Software. Volume 47, Issue 3. 2012
Bruno B., Mastrogiovanni F., Sgorbissa A., Vernazza T., and Zaccaria R. "Analysis of human behavior recognition algorithms based on acceleration data". In: IEEE Int Conf on Robotics and Automation (ICRA), pp. 1602-1607. 2013
Bruno B., Mastrogiovanni F., Sgorbissa A., Vernazza T., and Zaccaria R. "Human Motion Modeling and Recognition: A computational approach". In: IEEE International Conference on Automation Science and Engineering (CASE). pp 156-161. 2012
Hofmann T. "Probabilistic Latent Semantic Indexing". In: Twenty-Second Annual International SIGIR Conference....
In this chapter, we discussed the concepts behind unsupervised and semi-supervised machine learning, and their Bayesian treatment. We learned two important Bayesian unsupervised models: the Bayesian mixture model and LDA. We discussed in detail the bgmm package for the Bayesian mixture model, and the topicmodels and lda packages for topic modeling. Since the subject of unsupervised learning is vast, we could only cover a few Bayesian methods in this chapter, just to give a flavor of the subject. We have not covered semi-supervised methods using both item labeling and feature labeling. Interested readers should refer to more specialized books in this subject. In the next chapter, we will learn another important class of models, namely neural networks.