Chapter 4: Ingesting Data in Azure Data Explorer
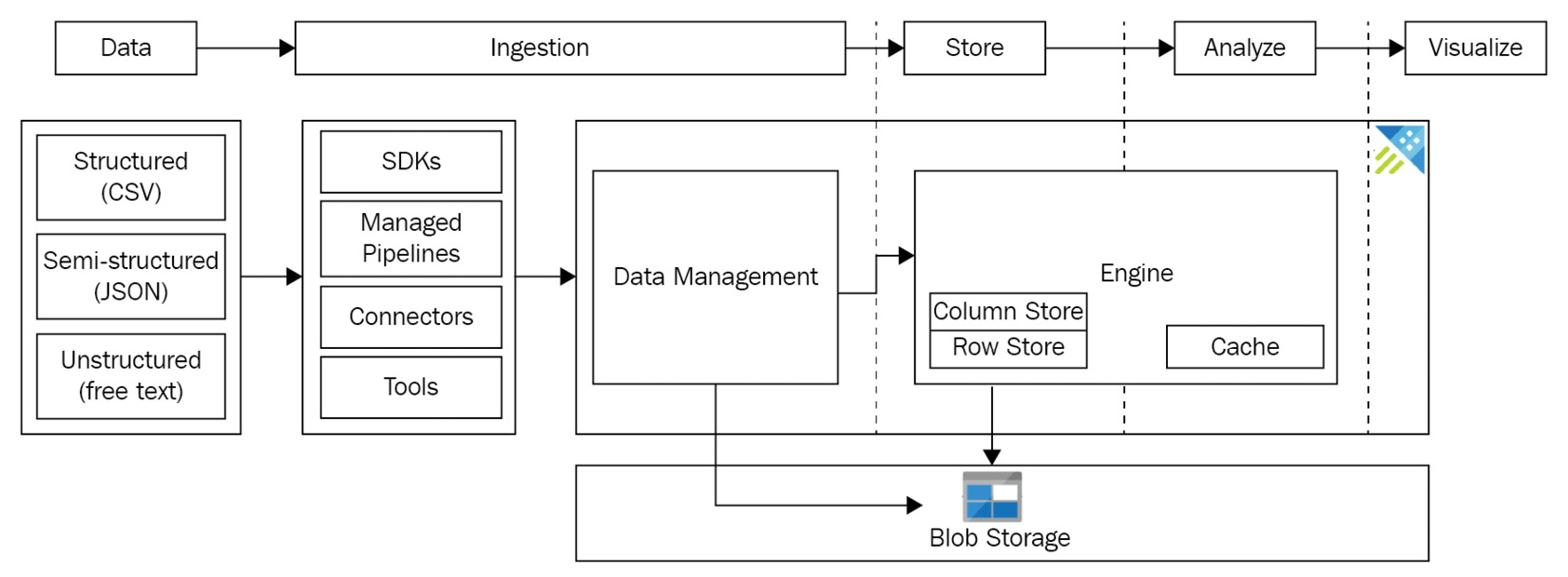
In the previous chapters, we created our Azure Data Explorer (ADX) clusters and databases, learned how to use the Data Explorer Web UI, executed our first Kusto Query Language (KQL) query. Now, we are ready to look at data ingestion in detail and start to ingest data. Data ingestion is the process of taking data from an external source and importing it into your big data solution, in our case, ADX. As you will soon see, once the data has been ingested, we can begin to analyze the data and generate visuals such as graphs and reports.
In this chapter, we will introduce data ingestion and discuss the different types of data (structured, semi-structured, and unstructured). Then we will examine the different data ingestion methods that ADX supports and learn how ADX ingests data via its Data management service, which we introduced in Chapter 1, Introducing Azure Data Explorer.
Next, we will learn about schema mapping, which is the process...