


Using the Metadata and Stored Procedure activities
In this recipe, we shall create a pipeline that fetches some metadata from an Azure storage container and stores it in an Azure SQL database table. You will work with two frequently used activities, the Metadata activity and the Stored Procedure activity.
Getting ready
- In the first recipe, we created two datasets and two linked services. We shall be using the
AzureSqlDatabaseandOrchestrationAzureBlobStoragelinked services in this recipe as well, so if you did not create them before, please go through the necessary steps in the previous recipe. - We shall be using
AzureSQLDatabase. If you haven’t done so already, create theFileMetadatatable and the stored procedure to insert the data as described in the Technical requirements section of this chapter.
How to do it…
- Create a new pipeline in the Author tab, and call it
pl_orchestration_recipe_2. - Create a new dataset named
CsvDataFolder, pointing to the Azure Storage container (adforchestrationstorage) we specified in the Technical requirements section. Use the delimited text file format. This time, do not specify the filename; leave it pointing to the data container itself. Use the same linked service for Azure Blob Storage as we used in the previous recipe. - From the Activities pane on the left, find the Get Metadata activity (under the General tab) and drag it onto the pipeline canvas. Using the configuration tabs at the bottom, configure it in the following way:
- In the General tab, rename this Metadata activity
CsvDataFolder Metadata. - In the Source tab, pick the
CsvDataFolderdataset. In the same tab, under Field list, use the New button to add two fields, and select Item Name and Last Modified as the values for those fields:
Figure 2.16: Get Metadata activity configuration
- In the General tab, rename this Metadata activity
- In the Activities pane, find the Stored Procedure activity (on the General tab) and drag it onto the canvas. In the pipeline canvas, connect the CsvDataFolder Metadata activity to the Stored Procedure activity.
- Configure the Stored Procedure activity in the following way:
- In the General tab, change the activity name to
Insert Metadata. - In the Settings tab, specify the linked service (
AzureSqlDatabase) and the name of the stored procedure:[dbo].[InsertFileMetadata]. - In the same Settings tab, click on Import Parameters to display the text fields to specify the parameters for the Stored Procedure activity. Use the following values:
- FileName:
@activity('CsvDataFolder Metadata').output.itemName - ModifiedAt:
@convertFromUtc(activity('CsvDataFolder Metadata').output.lastModified, 'Pacific Standard Time') - UpdatedAt:
@convertFromUtc(utcnow(), 'Pacific Standard Time'):
Figure 2.17: Stored Procedure activity configuration
- FileName:
- In the General tab, change the activity name to
- Run your pipeline in Debug mode. After the run is done, go to AzureSqlDatabase and verify that the FileMetadata table is populated with one record: the last-modified date of the folder where we keep the
.csvfiles. - Do not forget to publish your pipeline in order to save your changes.
How it works…
In this simple recipe, we introduced two new activities. In step 2, we have used the Metadata activity, with the dataset representing a folder in our container. In this step, we were only interested in the item name and the last-modified date of the folder. In step 3, we added a Stored Procedure activity, which allows us to directly invoke a stored procedure in the remote database. In order to configure the Stored Procedure activity, we needed to obtain the parameters (itemName, lastModified, and UpdatedAt). The formulas used in step 5 (such as @activity('CsvDataFolder Metadata').output.itemName) define which activity the value is coming from (the CsvDataFolder Metadata activity) and which parts of the output are required (output.itemName). We have used the built-in convertFromUtc conversion function in order to present the time in a specific time zone (Pacific Standard Time, in our case).
There’s more…
In this recipe, we only specified the itemName and lastModified fields as the metadata outputs. However, the Metadata activity supports many more options. Here is the list of currently supported options from the Data Factory documentation at https://learn.microsoft.com/en-us/azure/data-factory/control-flow-get-metadata-activity#capabilities:
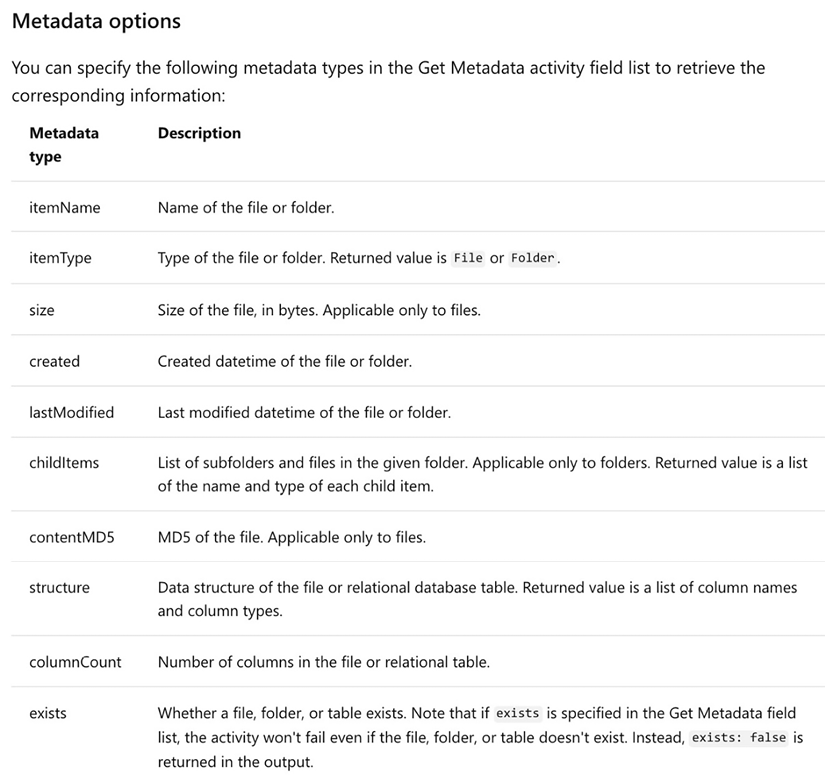
Figure 2.18: Metadata activity options
The Metadata type options that are available to you will depend on the dataset: for example, the contentMD5 option is only available for files, while childItems is only available for folders.