


Pausing/resuming an Azure Synapse SQL pool from Azure Data Factory
In this recipe, you will create a new Azure Data Factory pipeline that allows you to automatically pause and resume your Synapse dedicated SQLpool.
Getting ready
You need access to an Azure Synapse Workspace with a dedicated SQL pool for this recipe. Make sure your dedicated SQL pool before is paused before starting this recipe as you are going to resume it automatically using Azure Data Factory pipeline.
How to do it…
We shall start by designing a pipeline to resume a Synapse SQL pool with an Azure Data Factory pipeline, and then create a pipeline to pause it:
- Go to your Azure Data Factry studio, open the Author section and create a new pipeline. In the Activities section, choose Web. Rename the activity and the pipeline:
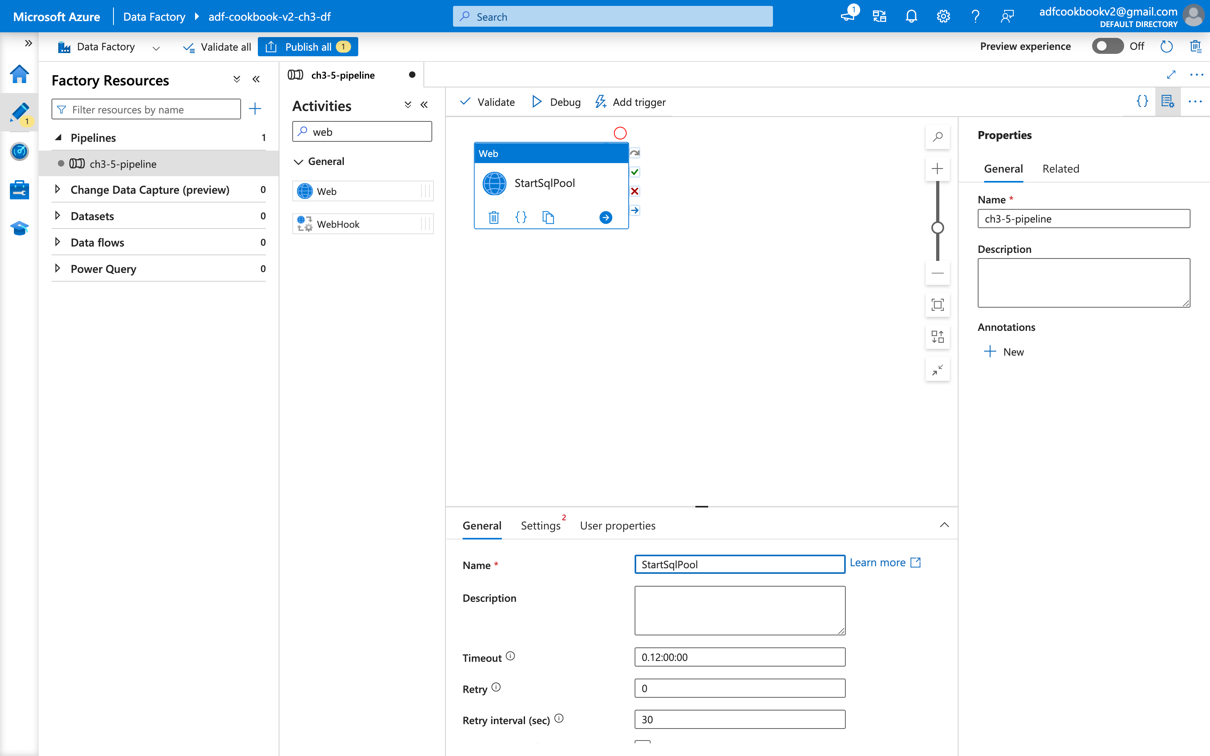
Go to the Settings tab, then copy and paste the following text into URL textbox:https://management.azure.com/subscriptions...



