

In this appendix, we will cover an introductory overview of some of the topics which were out of the scope of this book. But we will mention them in brief and end these topics with external links for you to explore further. This book as has already covered most of the advanced topics in deep reinforcement learning theory as well as active research domains.

There are many continuous action space algorithms in deep reinforcement learning topology. Some of them, which we covered earlier in Chapter 4, Policy Gradients, were mainly stochastic policy gradients and stochastic actor-critic algorithms. Stochastic policy gradients were associated with many problems such as difficulty in choosing step size owing to the non-stationary data due to continuous change in observation and reward distribution, where a bad step would adversely affect the learning of the policy network parameters. Therefore, there was a need for an approach that can restrict this policy search space and avoid bad steps while training the policy network parameters.
Here, we will try to cover some of the advanced continuous action space algorithms:
- Trust region policy optimization
- Deterministic policy gradients
Trustregion policy optimization (TRPO) is an iterative approach for optimizing policies. TRPO optimizes large nonlinear policies. TRPO restricts the policy search space by applying constraints on the output policy distributions. In order to do this, KL divergence loss function (
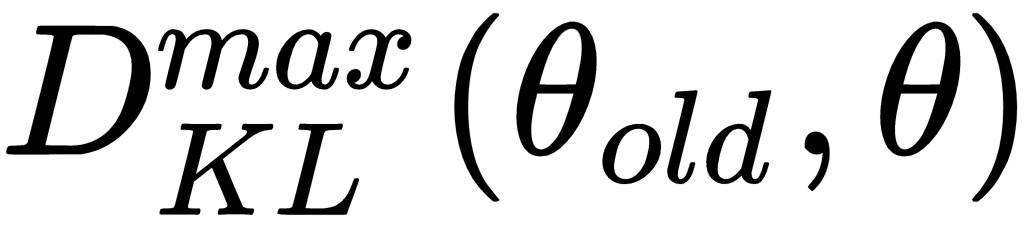
) is used on the policy network parameters to penalize these parameters. This KL divergence constraint between the new and the old policy is called the trust region constraint. As a result of this constraint large scale changes don't occur in the policy distribution, thereby resulting in early convergence of the policy network.
TRPO was published by Schulman et. al. 2017 in the research publication named Trust Region Policy Optimization (https://arxiv.org/pdf/1502.05477.pdf). Here they have mention the experiments demonstrating the robust performance of TRPO on different tasks such as learning simulated robotic swimming, playing Atari games, and many more. In order to study TRPO in detail, please follow the arXiv link of the publication: https://arxiv.org/pdf/1502.05477.pdf.
Deterministic policy gradients was proposed by Silver et. al. in the publication named Deterministic Policy Gradient Algorithms (http://proceedings.mlr.press/v32/silver14.pdf). In continuous action spaces, policy improvement with greedy approach becomes difficult and requires global optimization. Therefore, it is better and tractable to update the policy network parameters in the direction of the gradient of the Q function, as follows:
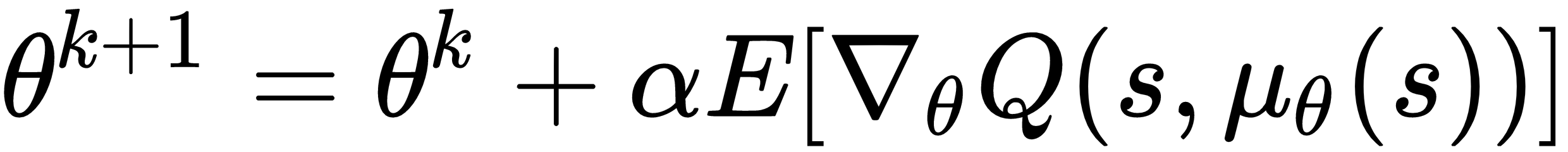
where,
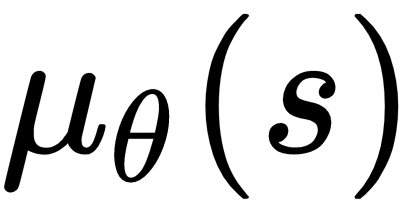
is the deterministic policy, α is the learning rate and θ representing the policy network parameters. By applying the chain rule, the policy improvement can be shown as follows:
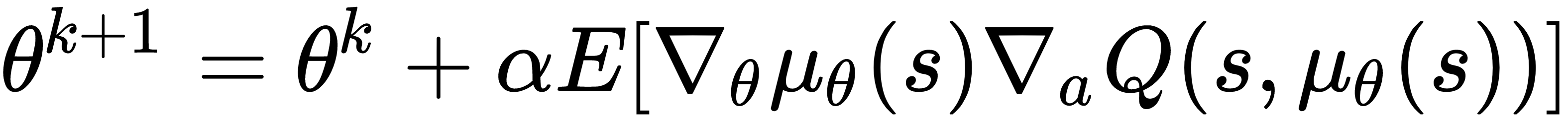
The preceding update rule can be incorporated into a policy networks where the parameters are updated using stochastic gradient ascent. This can be realized as a deterministic actor-critic method where the critic estimates the action-value function while the actor derives its gradients from the critic to update its parameters. As mentioned in Deterministic Policy Gradient Algorithms (http://proceedings.mlr.press/v32/silver14.pdf) by Silver et. al., post experimentation, they were able to successfully conclude that the deterministic policy gradients are more efficient than their stochastic counterparts. Moreover, deterministic actor-critic outperformed its stochastic counterpart by a significant margin. A detailed explanation of this topic is out of the scope of this book. So please go to the research publication link mentioned previously.
Two scoring mechanisms were used to evaluate the approaches mentioned in Chapter 14, Deep Reinforcement Learning in NLP, as follows:
One of the biggest challenges in sequential models in NLP used in machine translation, text summarization, image captioning, and much more is an adequate metric for evaluation.
Suppose your use case is machine translation; you have a German phrase and there are multiple English translations of it. All of them look equally good. So, how do you evaluate a machine translation system if there are multiple equally good answers? This is unlike image recognition, where the target has only one right answer and not multiple, equally good right answers.
For example:
- German sentence: Die Katze ist auf der Matte
A multiple reference human-generated translation of the preceding German sentence is as follows:
- The cat is on the mat
- There is a cat on the mat
If the target is just one right answer, the accuracy measurement is easy, but if there are multiple equally correct possibilities, then how is the accuracy in such a case measured? In this section, we will study BLEU score, which is an evaluation metric to measure accuracy in such cases of multiple equally correct answers.
BLEU score was published by Papineni et. al. 2002 in their research publication named BLEU: a Method for Automatic Evaluation of Machine Translation (https://www.aclweb.org/anthology/P02-1040.pdf). BLEU stands for Bi-Lingual Evaluation Understudy. For a given machine-generated output (say translation in the case of machine translation or summary in the case of text summarization), the score measures the goodness of the output, that is, how much close the machine-generated output is to any of the possible human-generated references (possible actual outputs). Thus, the closer the output text is to any human-generated reference, the higher will be the BLEU score.
The motivation behind BLEU score was to devise a metric that can evaluate machine-generated text with respect to human-generated references just like human evaluators. The intuition behind BLEU score is that it considers the machine-generated output and explores if these words exist in at least one of the multiple human-generated references.
Let's consider the following example:
- Input German text: Der Hund ist unter der Decke
Say we have two human-generated references which are as follows:
- Reference 1: The dog is under the blanket
- Reference 2: There is a dog under the blanket
And say our machine translation generated a terrible output, which is "the the the the the the"
Thus, the precision is given by the following formula:

As such, the following applies:

Since the appears six times in the output and each the appears in at least one of the reference texts, precision is 1.0. The issue arises because of the basic definition of precision, which is defined as the fraction of the predicted output that appears in the actual output (reference). Thus, the occurring in the predicted output is the only text, and since it appears in the references, the resulting precision is 1.0.
Therefore, the definition of precision is modified to get a modified formula where a clip count is put. Here, clip count is the maximum number of times a word appears in any of the references. Thus, modified precision is defined as the maximum number of times a word appears in any of the references divided by the total number of appearances of that word in the machine-generated output.
For the preceding example, the modified precision would be given as:

Till now, we have considered each word in isolated form, that is, in the form of a unigram. In BLEU score, you also want to look at words in pairs and not just in isolation. Let's try to calculate the BLEU score with the bi-gram approach, where bi-gram means a pair of words appearing next to each other.
Let's consider the following example:
- Input German text: Der Hund ist unter der Decke
Say we have two human-generated references, which are as follows:
- Reference 1: The dog is under the blanket
- Reference 2: There is a dog under the blanket
Machine-generated output: The dog the dog the dog under the blanket
Bi-grams in the machine-generated output | Count | Countclip (maximum occurrences of the bi-gram in any one of the references) |
the dog | 3 | 1 |
dog the | 2 | 0 |
dog under | 1 | 0 |
under the | 1 | 1 |
the blanket | 1 | 1 |
Therefore, the modified bi-gram precision would be the ratio of the sum of bi-gram countclips and the sum of bi-gram counts, that is:

Thus, we can create the following precision formulae for uni-grams, bi-grams, and n-grams as follows:
- p1 = precision for uni-grams, where:

- p2 = precision for bi-grams, where:

- pn = precision for n-grams, where:

The modified precisions calculated on uni-grams, bi-grams, or even any n-grams allow you to measure the degree to which the machine-generated output text is similar to the human-generated references. If the machine-generated text is exactly similar to any one of the human-generated references then:

Let's put all the pi scores together to calculate the final BLEU score for the machine-generated output. Since, pn is the BLEU score on n-grams only (that is, modified precision on n-grams), the combined BLEU score where nmax = N is given by the following:

BP is called brevity penalty. This penalty comes into the picture if the machine-generated output is very short. This is because in case of short output sequence most of the words occurring in that have a very high chance of appearing in the human-generated references. Thus, brevity penalty acts as an adjustment factor which penalises the machine-generated text when it's shorter than the shortest human-generated output reference for that input.
Brevity penalty (BP) is given by the following formula:

where:
len(MO) = length of the machine-generated output
slen(REF) = length of the shortest human-generated reference output
For more details, please check the publication on BLEU score by Papineni et. al. 2002 (https://www.aclweb.org/anthology/P02-1040.pdf).
ROUGE stands for Recall Oriented Understudy for Gisting Evaluation. It is also a metric for evaluating sequential models in NLP especially automatic text summarization and machine translation. ROUGE was proposed by CY Lin in the research publication named ROUGE: A Package for Automatic Evaluation of Summaries (http://www.aclweb.org/anthology/W04-1013) in 2004.
ROUGE also works by comparing the machine-generated output(automatic summaries or translation) against a set of human-generated references.
Let's consider the following example:
- Machine-generated output: the dog was found under the bed
- Human-generated reference: the dog was under the bed
Therefore, precision and recall in the context of ROUGE is shown as follows:

Thus, recall = 6/6 = 1.0.
If recall is 1.0, it means that all the words in the human-generated reference is captured by the machine-generated output. There can be a case that machine-generated output might be extremely long. Therefore, while calculating recall, the long machine-generated output has a high chance to cover most of the human-generated reference words. As a result, precision comes to the rescue, which is computed as shown as follows:

Thus, precision (for the preceding example) = 6/7 = 0.86
Now, if the machine-generated output had been the big black dog was found under the big round bed, then,

,

This shows that the machine-generated output isn't appropriate since it contains a good amount of unnecessary words. Therefore, we can easily figure out that only recall isn't sufficient, and as a result both recall and precision should be used together for evaluation. Thus, F1-score which is calculated as the harmonic mean of recall and precision, as shown as follows is a good evaluation metric in such cases:

- ROUGE-1 refers to the overlap of unigrams between the machine-generated output and human-generated references
- ROUGE-2 refers to the overlap of bi-grams between the machine-generated output and human-generated references
Let's understand more about ROUGE-2 with the following example:
- Machine-generated output: the dog was found under the bed
- Human-generated reference: the dog was under the bed
Bigrams of the machine-generated output that is the dog was found under the bed:
"the cat"
"cat was"
"was found"
"found under"
"under the"
"the bed"
Bigrams of the human-generated reference that is the dog was under the bed:
"the dog"
"dog was"
"was under"
"under the"
"the bed"
Therefore:


Thus, ROUGE-2Precision shows that 67% of the bi-grams generated by the machine overlap with the human-generated reference.
This appendix covered the basic overview of ROUGE scoring in sequential models in NLP. For further details on ROUGE-N, ROUGE-L and ROUGE-S please go through the research publication of ROUGE: A Package for Automatic Evaluation of Summaries (http://www.aclweb.org/anthology/W04-1013) by CY Lin.
As a part of appendix, we covered a basic overview of continuous action space algorithms of the deep reinforcement learning topology, where we covered trust region policy optimization and deterministic policy gradients in brief. We also learned about the BLEU and ROUGE scores being actively used for evaluation in NLP-based sequential models.
Finally, I would like to say that deep reinforcement learning is still a new topic as tons of more algorithms will be developed. But the most important thing that will help you to understand and explore those yet-to-be-discovered future algorithms will be the strong hold on the basics that this book has covered.
The rest of the chapter is locked
You have been reading a chapter from
Reinforcement Learning with TensorFlowPublished in: Apr 2018Publisher: PacktISBN-13: 9781788835725
Register for a free Packt account to unlock a world of extra content!
A free Packt account unlocks extra newsletters, articles, discounted offers, and much more. Start advancing your knowledge today.
undefined
Unlock this book and the full library FREE for 7 days
Get unlimited access to 7000+ expert-authored eBooks and videos courses covering every tech area you can think of
Renews at $15.99/month. Cancel anytime