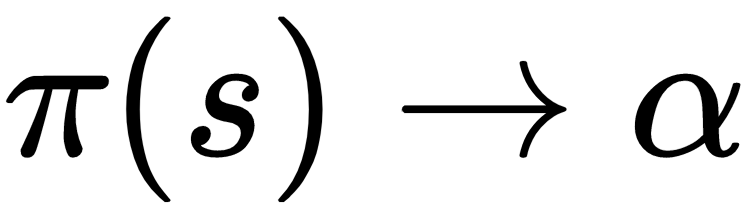The Markov decision process, better known as MDP, is an approach in reinforcement learning to take decisions in a gridworld environment. A gridworld environment consists of states in the form of grids, such as the one in the FrozenLake-v0 environment from OpenAI gym, which we tried to examine and solve in the last chapter.
The MDP tries to capture a world in the form of a grid by dividing it into states, actions, models/transition models, and rewards. The solution to an MDP is called a policy and the objective is to find the optimal policy for that MDP task.
Thus, any reinforcement learning task composed of a set of states, actions, and rewards that follows the Markov property would be considered an MDP.
In this chapter, we will dig deep into MDPs, states, actions, rewards, policies, and how to solve them using Bellman equations. Moreover, we will cover the basics of Partially Observable MDP and their complexity in solving. We will also cover the exploration...