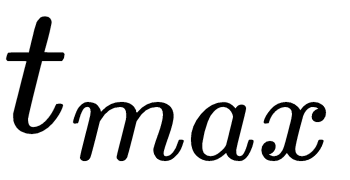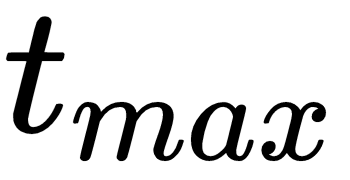So far, we have covered most of the important topics, such as the Markov Decision Processes, Value Iteration, Q-learning, Policy Gradients, deep-Q networks, and Actor Critic Algorithms. These form the core of the reinforcement learning algorithms. In this chapter, we will continue our search from where we left off in Actor Critic Algorithms, and delve into the advanced asynchronous methods used in deep reinforcement learning, and its most famous variant, the asynchronous advantage actor-critic algorithm, better known as the A3C Algorithm.
But, before we start with the A3C algorithm, let's revise the basics of the Actor Critic Algorithm covered in Chapter 4, Policy Gradients. If you remember, the Actor Critic Algorithm has two components:
- Actor
- Critic
The Actor takes the current environment state and determines best action to take, while the Critic plays a policy-evaluation role by taking in the environment state and action, and returns a score depicting how good...