





















































As already mentioned, an MDP is a reinforcement learning approach in a gridworld environment containing sets of states, actions, and rewards, following the Markov property to obtain an optimal policy. MDP is defined as the collection of the following:
- States: S
- Actions: A(s), A
- Transition model: T(s,a,s') ~ P(s'|s,a)
- Rewards: R(s), R(s,a), R(s,a,s')
- Policy:
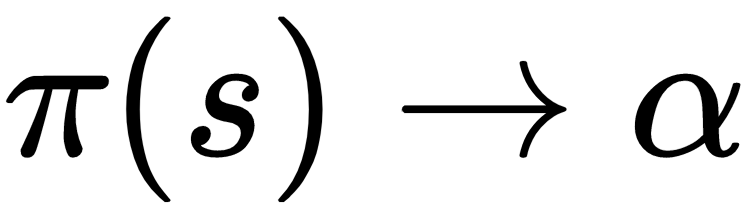 is the optimal policy
is the optimal policy
In the case of an MDP, the environment is fully observable, that is, whatever observation the agent makes at any point in time is enough to make an optimal decision. In case of a partially observable environment, the agent needs a memory to store the past observations to make the best possible decisions.
Let's try to break this into different lego blocks to understand what this overall process means.




















