


Using memory to overcome partial observability
A memory is nothing but a way of processing a sequence of observations as the input to the agent policy. If you worked with other types of sequence data with neural networks, such as in time series prediction or natural language processing (NLP), you can adopt similar approaches to use observation memory as the input your RL model.
Let's go into more details of how this can be done.
Stacking observations
A simple way of passing an observation sequence to the model is to stitch them together and treat this stack as a single observation. Denoting the observation at time  as
as  , we can form a new observation
, we can form a new observation  to be passed to the model as follows:
to be passed to the model as follows:
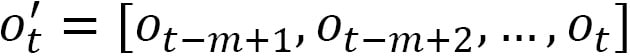
where  is the length of the memory. Of course, for
is the length of the memory. Of course, for  , we need to somehow initialize the earlier parts of the memory, such as using vectors of zeros that are the same dimension as
, we need to somehow initialize the earlier parts of the memory, such as using vectors of zeros that are the same dimension as  .
.
In fact, simply stacking observations is how the original DQN work handled...