


Chapter 8: Model-Based Methods
All of the deep reinforcement learning (RL) algorithms we have covered so far were model-free, which means they did not assume any knowledge about the transition dynamics of the environment but learned from sampled experiences. In fact, this was a quite deliberate departure from the dynamic programming methods to save us from requiring a model of the environment. In this chapter, we swing the pendulum back a little bit and discuss a class of methods that rely on a model, called model-based methods. These methods can lead to improved sample efficiency by several orders of magnitude in some problems, making it a very appealing approach, especially when collecting experience is as costly as in robotics. Having said this, we still will not assume that we have such a model readily available, but we will discuss how to learn one. Once we have a model, it can be used for decision-time planning and improving the performance of model-free methods.
This important...
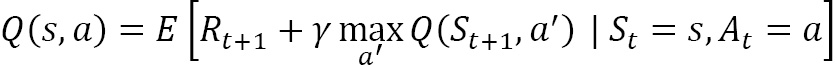
 is a random variable along with
is a random variable along with  . On the other hand, if we know the probability distribution of
. On the other hand, if we know the probability distribution of  and
and  , we can...
, we can...