


Chapter 11: Achieving Generalization and Overcoming Partial Observability
Deep reinforcement learning (RL) has achieved what was impossible with the earlier AI methods, such as beating world champions in games like Go, Dota 2, and StarCraft II. Yet, applying RL to real-world problems is still challenging. Two important obstacles to this end are generalization of trained policies to a broad set of environment conditions and developing policies that can handle partial observability. As we will see in the chapter, these are closely related challenges, for which we will present solution approaches.
Here is what we will cover in this chapter:
- Focusing on generalization in reinforcement learning
- Enriching agent experience via domain randomization
- Using memory to overcome partial observability
- Quantifying generalization via CoinRun
These topics are critical to understand for a successful implementation of RL in real-world settings. So, let's dive right in...
 as
as  , we can form a new observation
, we can form a new observation  to be passed to the model as follows:
to be passed to the model as follows: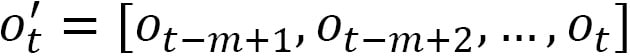
 is the length of the memory. Of course, for
is the length of the memory. Of course, for  , we need to somehow initialize the earlier parts of the memory, such as using vectors of zeros that are the same dimension as
, we need to somehow initialize the earlier parts of the memory, such as using vectors of zeros that are the same dimension as  .
.