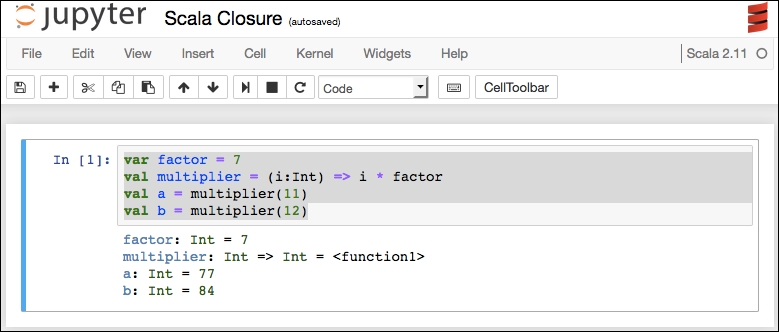
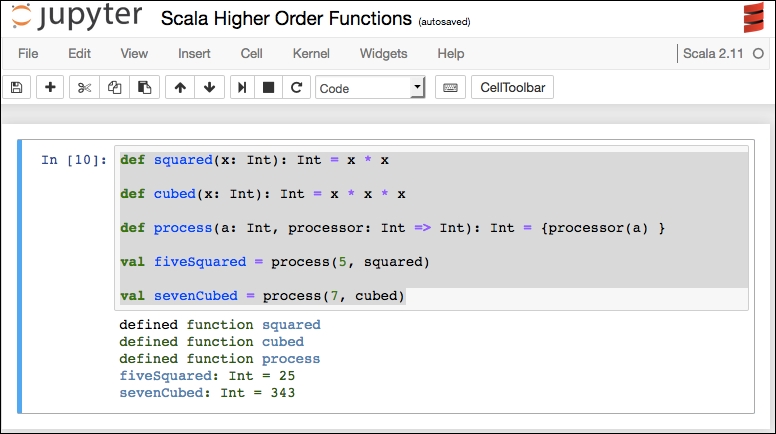
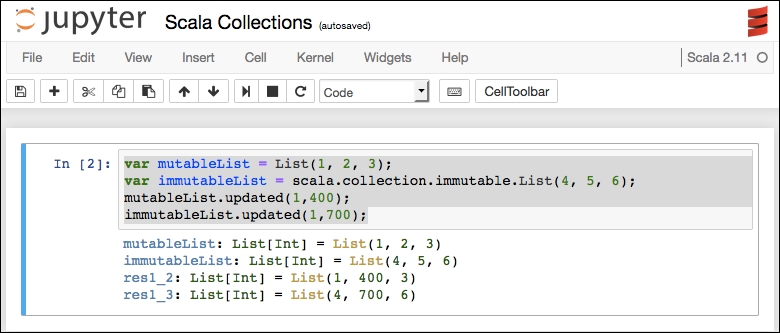
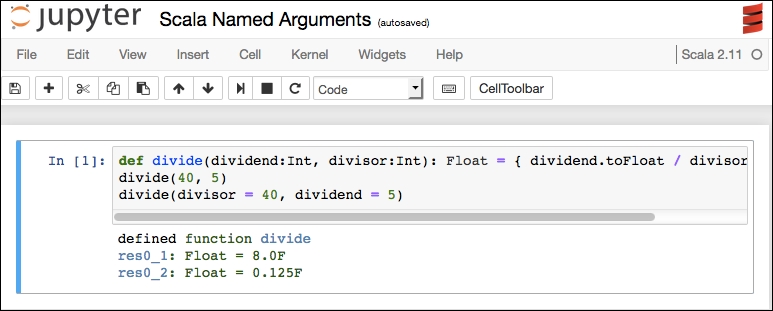
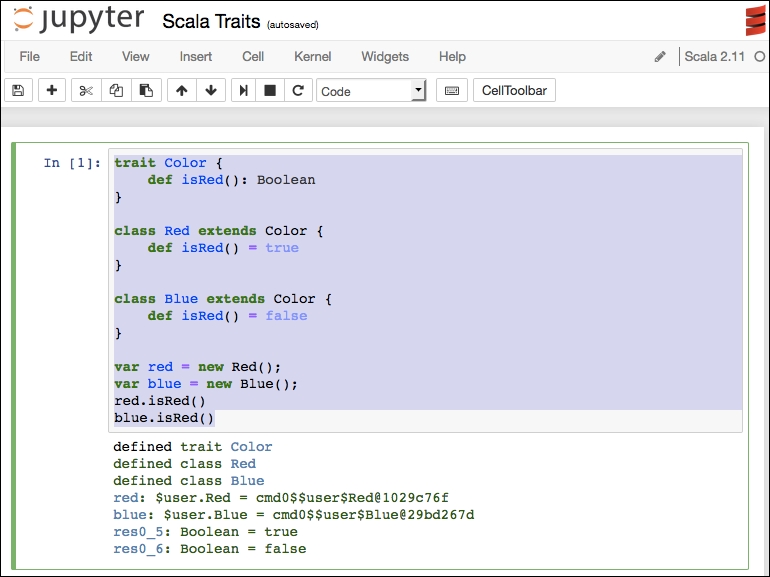
Scala does not have pandas, but we can emulate some of that logic with our own coding. We will use the same Titanic dataset used in
Chapter 2
, Jupyter Python Scripting, from http://www.kaggle.com/c/titanic-gettingStarted/download/train.csv, which we have downloaded in our local space.
We can then use similar coding as was used in
Chapter 2
, Jupyter Python Scripting, on pandas:
import scala.io.Source;
val filename = "train.csv"
//PassengerId,Survived,Pclass,Name,Sex,Age,SibSp,
Parch,Ticket,Fare,Cabin,Embarked
//1,0,3,"Braund, Mr. Owen Harris",male,22,1,0,A/5 21171,7.25,,S
var males = 0
var females = 0
var males_survived = 0
var females_survived = 0
for (line <- Source.fromFile(filename).getLines) {
var cols = line.split(",").map(_.trim);
var sex = cols(5);
if (sex == "male") {
males = males + 1;
if (cols(1).toInt == 1) {
males_survived = males_survived + 1;
}
}
if (sex == "female") {
females...