Python random numbers in Jupyter
For many analyses, we are interested in calculating repeatable results. However, a lot of analysis relies on random numbers being used. In Python, you can set the seed for the random number generator to achieve repeatable results with the random_seed() function.
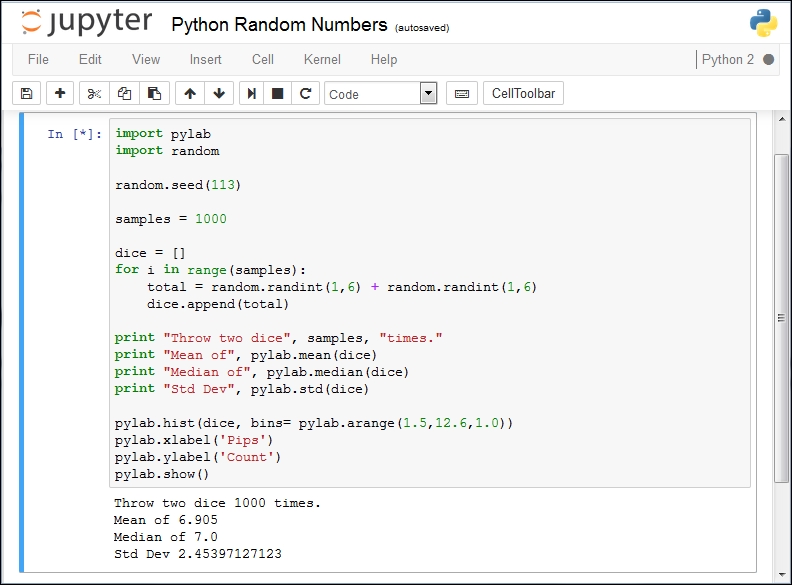
In this example, we simulate rolling a pair of dice and looking at the outcome.
The script we are using is this:
import pylab
import random
random.seed(113)
samples = 1000
dice = []
for i in range(samples):
total = random.randint(1,6) + random.randint(1,6)
dice.append(total)
pylab.hist(dice, bins= pylab.arange(1.5,12.6,1.0))
pylab.show()
Once we have the script in Jupyter and execute it, we have this result:
I had added some more statistics. I'm not sure I would have counted on such a high standard deviation. If we increased the number of samples, this would increase.
The resulting graph was opened in a new window, much as it would be if you ran this script in another Python development environment...