


Spark exposes many SQL-like actions that can be taken upon a data frame. For example, we could load a data frame with product sales information in a CSV file:
from pyspark.sql import SparkSession spark = SparkSession(sc) df = spark.read.format("csv") \ .option("header", "true") \ .load("productsales.csv");df.show()
The example:
- Starts a
SparkSession(needed for most data access) - Uses the session to read a CSV formatted file, that contains a header record
- Displays initial rows
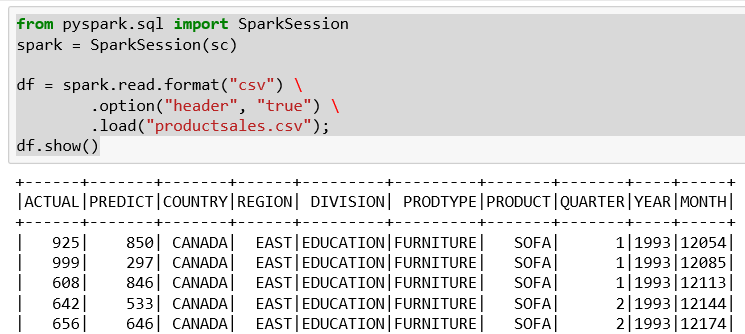
We have a few interesting columns in the sales data:
- Actual sales for the products by division
- Predicted sales for the products by division
If this were a bigger file, we could use SQL to determine the extent of the product list. Then the following is the Spark SQL to determine the product list:
df.groupBy("PRODUCT").count().show()The data frame groupBy function works very similar to the SQL Group By clause. Group By collects the items in the dataset according to the values in the column...