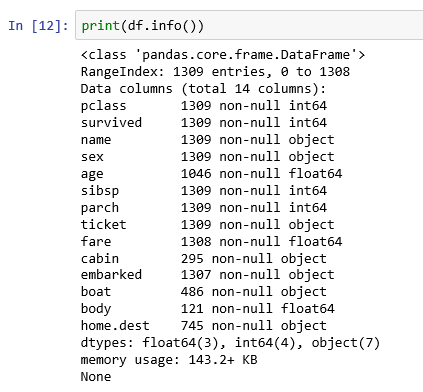
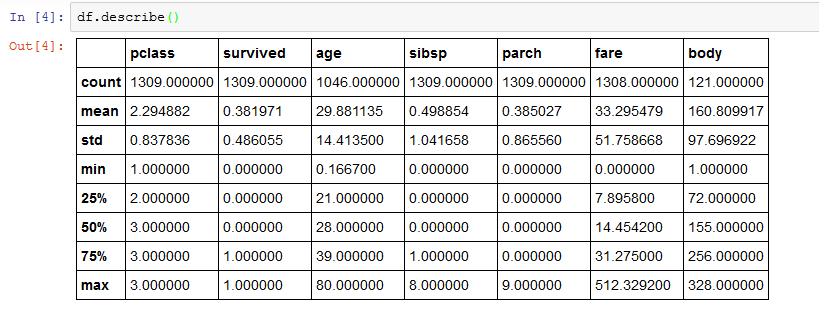
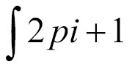Jupyter does none of the heavy lifting for analyzing data: all the work is done by programs written in a selected language. Jupyter provides the framework to run a variety of programming language modules. So, we have a choice how we analyze data in Jupyter.
A popular choice for data analysis programming is Python. Jupyter does have complete support for Python programming. We will look at a variety of programming solutions that might tax such a support system and see how Jupyter fairs.