


There are more functions built-in for working with data frames than we have used so far. If we were to take one of the data frames from a prior example in this chapter, the Titanic dataset from an Excel file, we could use additional functions to help portray and work with the dataset.
As a repeat, we load the dataset using the script:
import pandas as pddf = pd.read_excel('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic3.xls')
We can then inspect the data frame using the info function, which displays the characteristics of the data frame:
df.info()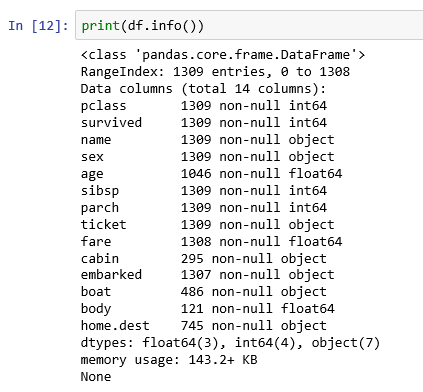
Some of the interesting points are as follows:
- 1309 entries
- 14 columns
- Not many fields with valid data in the
bodycolumn—most were lost - Does give a good overview of the types of data involved
We can also use the describe function, which gives us a statistical breakdown of the number columns in the data frame.
df.describe()This produces the following tabular display:
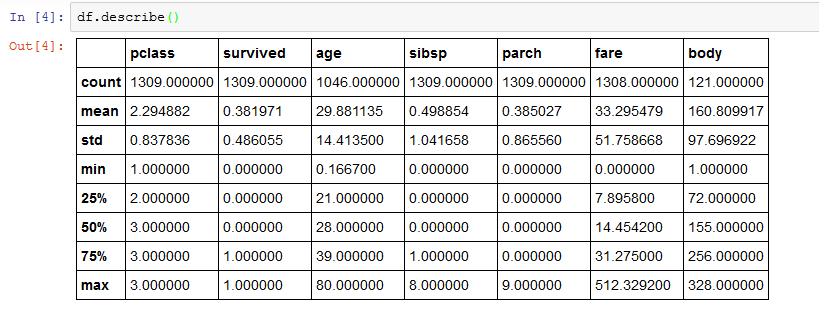
For each numerical column we have...