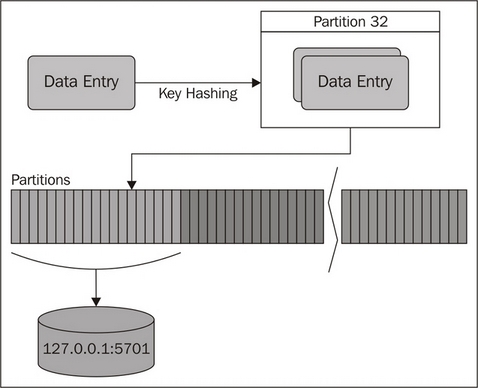
In order to be resilient, Hazelcast apportions the overall data into slices referred to as partitions, and spreads these across our cluster. To do this, it uses a consistent hashing algorithm on the data keys to consistently assign a piece of data to a particular partition, before assigning the ownership of an entire partition to a particular node. By default there are 271 partitions, however this is configurable using the hazelcast.map.partition.count property.
This process allows for transparent and automatic fragmentation of our data, but with tunable behavior, while allowing us to ensure that any shared risks (such as nodes running on the same hardware or sharing the same data center rack) are militated against.
We can visualize the partitioning process in the following diagram: