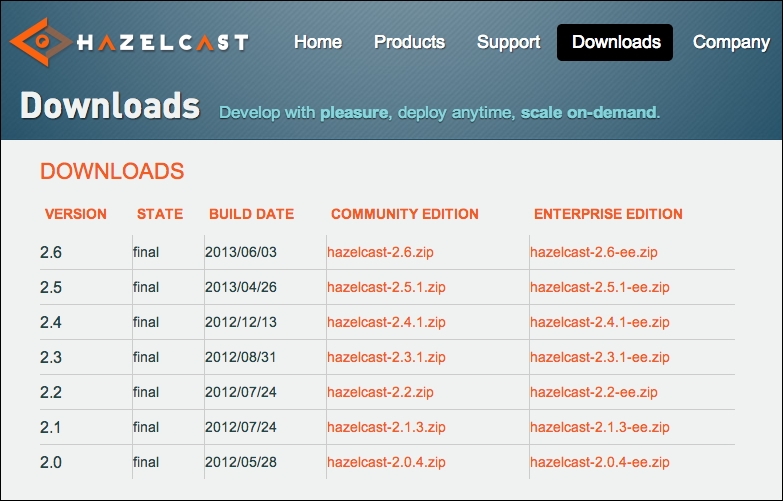
Simply put, we can think of Hazelcast as a library technology—a JAR file that we bring into our application's classpath, and integrate with in order to harness its data distribution capabilities. Now, there are many ways we could go about setting up an application to use various third-party libraries and dependencies. Most modern IDEs can do this for you. Dependency management or build tools such as Maven, Ant, or Gradle can automate it, and we could sort all of it out ourselves manually. But it's now time to jump in, head first into the deep end. In this chapter, we shall:
Download Hazelcast
Create a basic application around the technology
Explore the various simple storage collections
Fetch and search our stored data
Set limits and understand what happens when we reach these