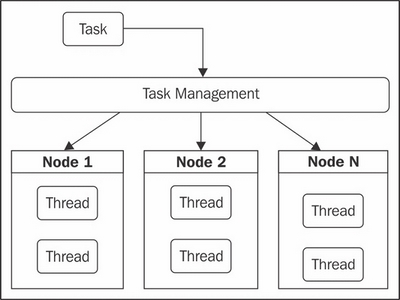
In addition to the distributed data storage, Hazelcast also provides us with an ability to share out computational power, in the form of a distributed executor. In this chapter, we shall:
Learn about the distributed executor service
Using futures for response retrieval
Single node and multi-node tasks
Forcing the location of execution
Aligning data with compute