Chapter 4. Divide and Conquer
One of the primary advantages of technologies like Hazelcast is the distributed nature of their data persistence; by fragmenting and scattering the held data across many diverse nodes we can achieve high levels of reliability, scalability, and performance. In this chapter we will investigate:
How data is split into partitions
How that data is backed up within the overall cluster
Replicating backups; synchronous versus asynchronous
Trade-off between read performance and consistency
How to silo groups of nodes together
How we can manage network partitioning (split brain syndrome)
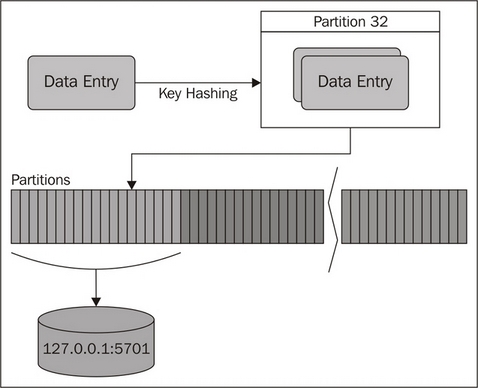
In order to be resilient, Hazelcast apportions the overall data into slices referred to as partitions, and spreads these across our cluster. To do this, it uses a consistent hashing algorithm on the data keys to consistently assign a piece of data to a particular partition, before assigning the ownership of an entire partition to a particular node. By default there are 271 partitions, however this is configurable using the hazelcast.map.partition.count property.
This process allows for transparent and automatic fragmentation of our data, but with tunable behavior, while allowing us to ensure that any shared risks (such as nodes running on the same hardware or sharing the same data center rack) are militated against.
We can visualize the partitioning process in the following diagram:
Backups everywhere and nowhere
As each node could disappear or be destroyed at any time without notice; in order to preserve the integrity of the overall persisted data, each partition is backed up on a number of other nodes and must be nodes other than the owner; an individual node can only hold each partition just once (either owning or backing up). Should a node die, the ownership of any partitions that were owned by the now defunct node will be migrated to one of the backups so that no apparent data loss is experienced. Additionally in the background, Hazelcast will start to replicate the migrated partitions over to another node to cater for the fact that there are now fewer backups available than was configured. This will restore resilience back to as it was configured. The number of backups that Hazelcast will create is configurable depending on your hardware's stability, appetite for risk, and available memory.
We can configure the number of backups to keep the method of creation;...
Now that we have created a cluster to house all our data, with a number of nodes holding both owned partitions and backups; but what happens if we need to scale? This could be for a number of reasons, for example, approaching the current memory capacity or our application is rather demanding and saturating a hardware resource. The solution in both cases is simple; add more nodes.
So if we were to start with a cluster of four nodes holding overall 4 million objects, each individual node would hold roughly 1 million owned objects (and a further 1 million backups). When we introduce a new node, Hazelcast reacts by assigning partitions from existing nodes to it. This will cause existing data to stream across to the new node taking on more and more partitions until it holds an overall fair share. The net result will be that each node now only holds approximately 8,00,000 owned objects (and a similar number of backups). In adding this new node we have created additional capacity...
Grouping and separating nodes
By default Hazelcast treats each instance as a completely separate node and as such will use any combination of the cluster nodes to hold copies (either for ownership or backups). This instantly introduces a problem where we run multiple JVM instances on the same machine (either physical or virtual). In that any host or hardware level issues that affect one JVM, might affect multiple at the same time, putting data resilience at risk.
To avoid this, we can configure Hazelcast to assign partitions not to an individual node, but to a defined group of nodes. Typically these groups of nodes will be known to share a common external risk or need to balance any differences in available memory; this siloing of nodes is referred to as partition grouping. There are currently two ways to configure a partition group:
Firstly, there exists an automatic process that handles the case of having multiple JVM instances running on the same machine; this is detected by having different...
We have seen that Hazelcast is capable of handling individual node outages, reacting to restore resilience where possible. However it's not just node failures that we have to be able to handle; it could also easily be an issue in the underlying network fabric that can lead to a situation know as split brain syndrome. As this happens away from our application, more at the infrastructure layer, there is very little we can do to prevent it from happening. But we should understand how the problem could affect our application and how the issue is handled when the underlying outage is resolved.
The primary issue for our application is where two (or more) sides of a network outage are able to operate perfectly in isolation. In theory, assuming there were backup copies of the data held on both sides of the split, we will continue to operate normally as two independent deployments. But what happens when the sides become visible again to each other, especially in the case where...
So we now know a little more of how Hazelcast apportions data into partitions, how these partitions are automatically assigned to a node or a partition group and how we might configure these to our needs. We have also investigated how it deals with issues, be it failure of an individual node or group of nodes within a defined silo, and how we recover it to restore resilience; or an underlying network fabric issue that creates a network split brain, and how we are able to cleanly bring multiple sides of the split back together and return to normal service.
Now that we have seen how things work behind the scenes to manage and distribute our data, we might need our application to know about some of these goings-on. In the next chapter we shall look at how our application can register its interest to be notified as things happen to support the cluster.