RL is not a new field. Many of the fundamental ideas in RL were introduced in the context of dynamic programming and optimal control throughout the past seven decades. However, successful RL implementations have taken off recently thanks to the breakthroughs in deep learning and more powerful computational resources. In this section, we talk about some of the application areas of RL together with some famous success stories. We will go deeper into the algorithms behind these implementations in the following chapters.
Games
Board and video games have been a research lab for RL, leading to many famous success stories in this area. The reasons of why games make good RL problems are as follows:
- Games are naturally about sequential decision-making with uncertainty involved.
- They are available as computer software, making it possible for RL models to flexibly interact with them and generate billions of data points for training. Also, trained RL models are then also tested in the same computer environment. This is as opposed to many physical processes for which it is too complex to create accurate and fast simulators.
- The natural benchmark in games are the best human players, making it an appealing battlefield for AI vs. human comparisons.
After this introduction, let's go into some of the most exciting RL work that made to the headlines.
TD-Gammon
The first famous RL implementation is TD-Gammon, a model that learned how to play super-human level backgammon - a two-player board game with 1020 possible configurations. The model was developed by Gerald Tesauro at the IBM Research in 1992. TD-Gammon was so successful that it created a great excitement in the backgammon community back then with the novel strategies it taught humans. Many methods used in that model (temporal-difference, self-play, use of neural networks) are still at the center of the modern RL implementations.
Super-human performance in Atari games
One of the most impressive and seminal works in RL was that of Volodymry Mnih and his colleagues at Google DeepMind that came out in 2015. The researchers trained RL agents that learned how to play Atari games better than humans by only using screen input and game scores, without any hand-crafted or game-specific features through deep neural networks. They named their algorithm deep Q-network (DQN), which is one of the most popular RL algorithms today.
Beating the world champions in Go, chess and Shogi
The RL implementation that perhaps brought the most fame to RL was Google DeepMind's AlphaGo. It was the first computer program to beat a professional player in the ancient board game of Go in 2015, and later the world champion Lee Sedol in 2016. This story was later turned into a documentary film with the same name. The AlphaGo model was trained using data from human expert moves as well as with RL through self-play. The later version, AlphaGo Zero reached a performance of defeating the original AlphaGo 100-0, which was trained via just self-play and without any human knowledge inserted to the model. Finally, the company released AlphaZero in 2018 that was able to learn the games of chess, shogi (Japanese chess) and Go to become the strongest player in history for each, without any prior information about the games except the game rules. AlphaZero reached this performance after only several hours of training on tensor processing units (TPUs). AlphaZero's unconventional strategies were praised by world-famous players such as Garry Kasparov (chess) and Yoshiharu Habu (shogi).
Victories in complex strategy games
RL's success later went beyond just Atari and board games, into Mario, Quake III Arena, Capture the Flag, Dota 2 and StarCraft II. Some of these games are exceptionally challenging for AI programs with the need for strategic planning, involvement of game theory between multiple decision makers, imperfect information and large number of possible actions and game states. Due to this complexity, it took enormous amount of resources to train those models. For example, OpenAI trained the Dota 2 model using 256 GPUs and 128,000 CPU cores for months, giving 900 years of game experience to the model per day. Google DeepMind's AlphaStar, which defeated top professional players in StarCraft II in 2019, required training hundreds of copies of a sophisticated model with 200 years of real-time game experience for each, although those models were initially trained on real game data of human players.
Robotics and autonomous systems
Robotics and physical autonomous systems are challenging fields for RL. This is because RL agents are trained in simulation to gather enough data; but a simulation environment cannot reflect all the complexities of the real-world. Therefore, those agents often fail in the actual task, which is especially problematic if the task is safety critical. In addition, these applications often involve continuous actions, which require different types of algorithms than DQN. Despite these challenges, on the other hand, there are numerous RL success stories in these fields. In addition, there is a lot of research on using RL in exciting applications such autonomous ground and air vehicles.
Elevator optimization
An early success story that proved RL can create value for real-world applications was about elevator optimization in 1996 by Robert Crites and Andrew Barto. The researchers developed an RL model to optimize elevator dispatching in a 10-story building with 4 elevator cars. This was a much more challenging problem than the earlier TD-gammon due to the possible number of situations the model can encounter, partial observability (the number of people waiting at different floors was not observable to the RL model), and the possible number of decisions to choose from. The RL model substantially improved the best elevator control heuristics of the time across various metrics such as average passenger wait-time and travel-time.
Humanoid robots and dexterous manipulation
In 2017, Nicolas Heess et al. of Google DeepMind were able to teach different types of bodies (humanoid ) various locomotion behaviors such as how to run, jump in a computer simulation. In 2018, Marcin Andrychowicz et al. of OpenAI trained a five-fingered humanoid hand that is able to manipulate a block from an initial configuration to a goal configuration. And in 2019, again researchers from OpenAI, Ilge Akkaya et al. were able to train a robot hand that can solve a Rubik's cube.
Figure 1.1 – OpenAI's RL model that solved Rubik's cube is trained in simulation (a) and deployed on a physical robot (b). (Image source: OpenAI Blog, 2019)
Both of the latter two models were trained in simulation and successfully transferred to physical implementation using domain randomization techniques (Figure 1.1).
Emergency response robots
In the aftermath of a disaster, using robots could be extremely helpful especially when operating in dangerous conditions. For example, robots could locate survivors in damaged structures, turn off gas valves Creating intelligent robots that operate autonomously would allow to scale emergency response operations and provide the necessary support to many more people than it is possible with manual operations.
Self-driving vehicles
Although a full self-driving car is too complex to solve with an RL model alone, some of the tasks could be handled by RL. For example, we can train RL agents for self-parking, and making decisions for when and how to pass a car on a highway. Similarly, we can use RL agents to execute certain tasks in an autonomous drone, such as how to take off, land, avoid collusions
Info
In a phenomenal success story that came in late 2020, Loon and Google AI deployed a superpressure balloon in the stratosphere that is controlled by a RL agent. You can read about this story at https://bit.ly/33RqQCh.
As in many areas, we see RL appearing as a competitive alternative to traditional controllers for vehicles.
Supply chain
Many decisions in supply chain are of sequential nature and involve uncertainty, for which RL is a natural approach. Some of these problems are as follows:
- Inventory planning is about deciding when to place a purchase order to replenish the inventory of an item and at what quantity. Ordering less than necessary causes shortages and ordering more than necessary causes excess inventory costs, product spoilage and inventory removal at reduced prices. RL models are used to make inventory planning decisions to decrease the cost of these operations.
- Bin packing is a common problem in manufacturing and supply chain where items arriving at a station are placed into containers to minimize the number of containers used, and to ensure smooth operations in the facility. This is a difficult problem that can be solved using RL.
Manufacturing
An area where RL will have a great impact is manufacturing, where a lot of manual tasks can potentially be carried out by autonomous agents at reduced costs and increased quality. As a result, many companies are looking into bringing RL to their manufacturing environment. Here are some example RL applications in manufacturing.
- Machine calibration is a task that is often handled by human experts in manufacturing environments, which is inefficient and error prone. RL models are often capable of achieving these tasks at reduced costs and increased quality.
- Chemical plant operations often involve sequential decision making, which are often handled by human experts or heuristics. RL agents are shown to be effectively controlling these processes with better final product quality and less equipment wear and tear.
- Equipment maintenance requires planning down-times to avoid costly breakdowns. RL models can effectively balance the cost of downtime and cost of a potential breakdown.
- In addition to the examples above, many successful RL applications in robotics can be transferred to manufacturing solutions.
Personalization and recommender systems
Personalization is arguably the area where RL has created the most business value so far. Big tech companies provide personalization as a service with RL algorithms running under the hood. Here are some examples.
- In advertising, the order and content of promotional materials delivered to (potential) customers is a sequential decision-making problem that can be solved using RL, leading to increased customer satisfaction and conversion.
- News recommendation is an area where Microsoft News has famously applied RL and increased visitor engagement by improving the article selection and the order of recommendation.
- Personalization of the artwork that you see for the titles on Netflix is handled by RL algorithms. With that, the viewers better identify the titles relevant to their interests.
- Personalized healthcare is becoming increasingly important as it provides more effective treatments at reduced costs. There are many successful applications of RL picking the right treatment for patients.
Smart cities
There are many areas RL can help improve how cities operate. Below are couple examples.
- In a traffic network with multiple intersections, the traffic lights should work in harmony to ensure the smooth flow of the traffic. It turns out that this problem can be modeled as a multi-agent RL problem and improve the existing systems for traffic light control.
- Balancing the generation and demand in electricity grids in real-time is an important problem to ensure the grid safety. One way of achieving this is to control the demand, such as charging electric vehicles and turning on air conditioning systems when there is enough generation, without sacrificing the service quality, to which RL methods have successfully been applied.
This list can go on for pages, but it should be enough to demonstrate the huge potential in RL. What Andrew Ng, a pioneer in the field, says about AI is very much true for RL as well.
Just as electricity transformed almost everything 100 years ago, today I actually have a hard time thinking of an industry that I don't think AI will transform in the next several years. ("Andrew Ng: Why AI is the new electricity;" Stanford News; March 15, 2017)
RL today is only at the beginning of its prime time; and you are making a great investment by putting effort to understand what RL is and what it has to offer. Now, it is time to get more technical and formally define the elements in a RL problem.
 Argentina
Argentina
 Australia
Australia
 Austria
Austria
 Belgium
Belgium
 Brazil
Brazil
 Bulgaria
Bulgaria
 Canada
Canada
 Chile
Chile
 Colombia
Colombia
 Cyprus
Cyprus
 Czechia
Czechia
 Denmark
Denmark
 Ecuador
Ecuador
 Egypt
Egypt
 Estonia
Estonia
 Finland
Finland
 France
France
 Germany
Germany
 Great Britain
Great Britain
 Greece
Greece
 Hungary
Hungary
 India
India
 Indonesia
Indonesia
 Ireland
Ireland
 Italy
Italy
 Japan
Japan
 Latvia
Latvia
 Lithuania
Lithuania
 Luxembourg
Luxembourg
 Malaysia
Malaysia
 Malta
Malta
 Mexico
Mexico
 Netherlands
Netherlands
 New Zealand
New Zealand
 Norway
Norway
 Philippines
Philippines
 Poland
Poland
 Portugal
Portugal
 Romania
Romania
 Russia
Russia
 Singapore
Singapore
 Slovakia
Slovakia
 Slovenia
Slovenia
 South Africa
South Africa
 South Korea
South Korea
 Spain
Spain
 Sweden
Sweden
 Switzerland
Switzerland
 Taiwan
Taiwan
 Thailand
Thailand
 Turkey
Turkey
 Ukraine
Ukraine
 United States
United States


 is more commonly used during abstract discussions, especially when the environment is assumed to be fully observable, although observation is a more general term: What the agent receives is always an observation, which is sometimes just the state itself, and sometimes a part of or a derivation from the state, depending on the environment. Don't get confused if you see them used interchangeably in some contexts.
is more commonly used during abstract discussions, especially when the environment is assumed to be fully observable, although observation is a more general term: What the agent receives is always an observation, which is sometimes just the state itself, and sometimes a part of or a derivation from the state, depending on the environment. Don't get confused if you see them used interchangeably in some contexts.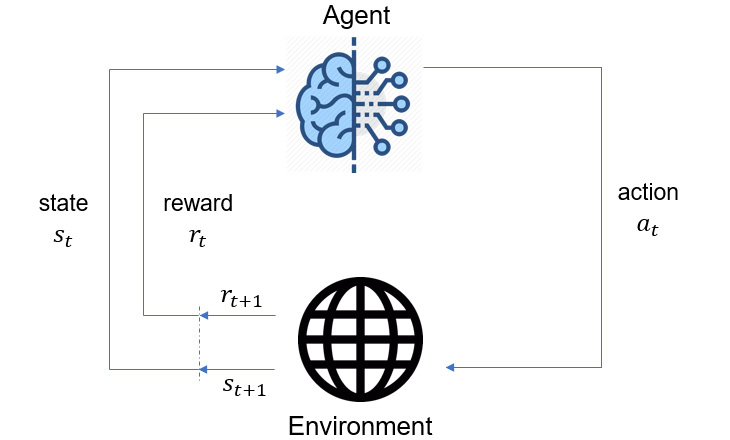
 grid. We now cast this as a RL problem to map the definitions provided above to the concepts in the game. The goal for a player is to place three of their marks in a vertical, horizontal or diagonal row to become the winner. If none of the players are able to achieve this before running out of the empty spaces on the grid, the game ends in a draw. Mid-game, a tic-tac-toe board might look like this:
grid. We now cast this as a RL problem to map the definitions provided above to the concepts in the game. The goal for a player is to place three of their marks in a vertical, horizontal or diagonal row to become the winner. If none of the players are able to achieve this before running out of the empty spaces on the grid, the game ends in a draw. Mid-game, a tic-tac-toe board might look like this: