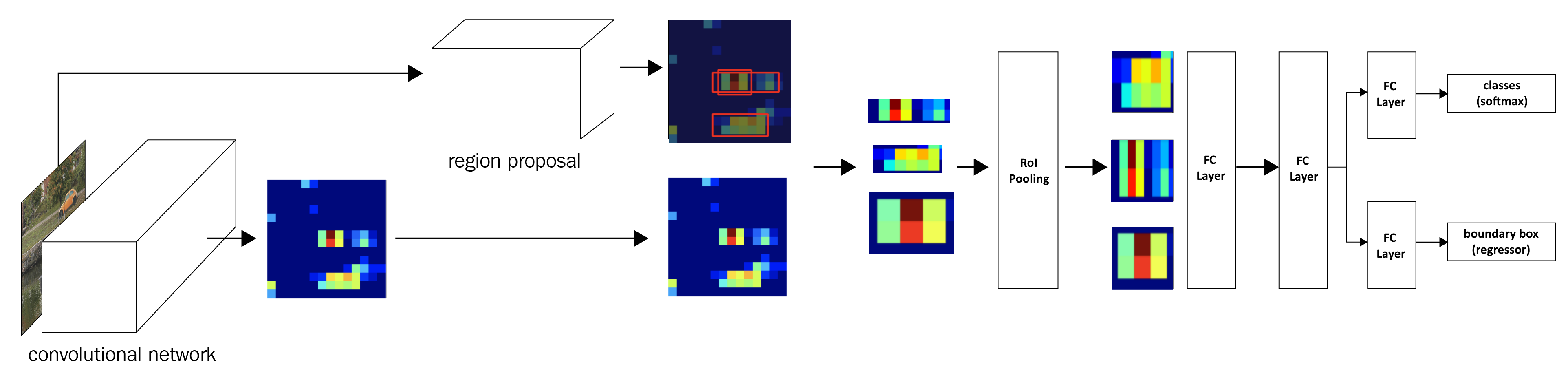
So far, in the previous chapters, we learned about performing image classification. Imagine a scenario where we are leveraging computer vision for a self-driving car. It is not only necessary to detect whether the image of a road contains the images of vehicles, a sidewalk, and pedestrians, but it is also important to identify where those objects are located. Various techniques of object detection that we will study in this chapter and the next will come in handy in such a scenario.
In this chapter and the next, we will learn about some of the techniques for performing object detection. We will start by learning about the fundamentals—labeling the ground truth of bounding box objects using a tool named ybat, extracting region proposals using the selectivesearch method, and defining the accuracy of bounding box predictions by using the Intersection...