


The groupBy operation doesn't involve any repartitioning. The groupBy operation converts the input stream into a grouped stream. The main function of the groupBy operation is to modify the behavior of the subsequent aggregate function. The following diagram shows how the groupBy operation groups the tuples of a single partition:
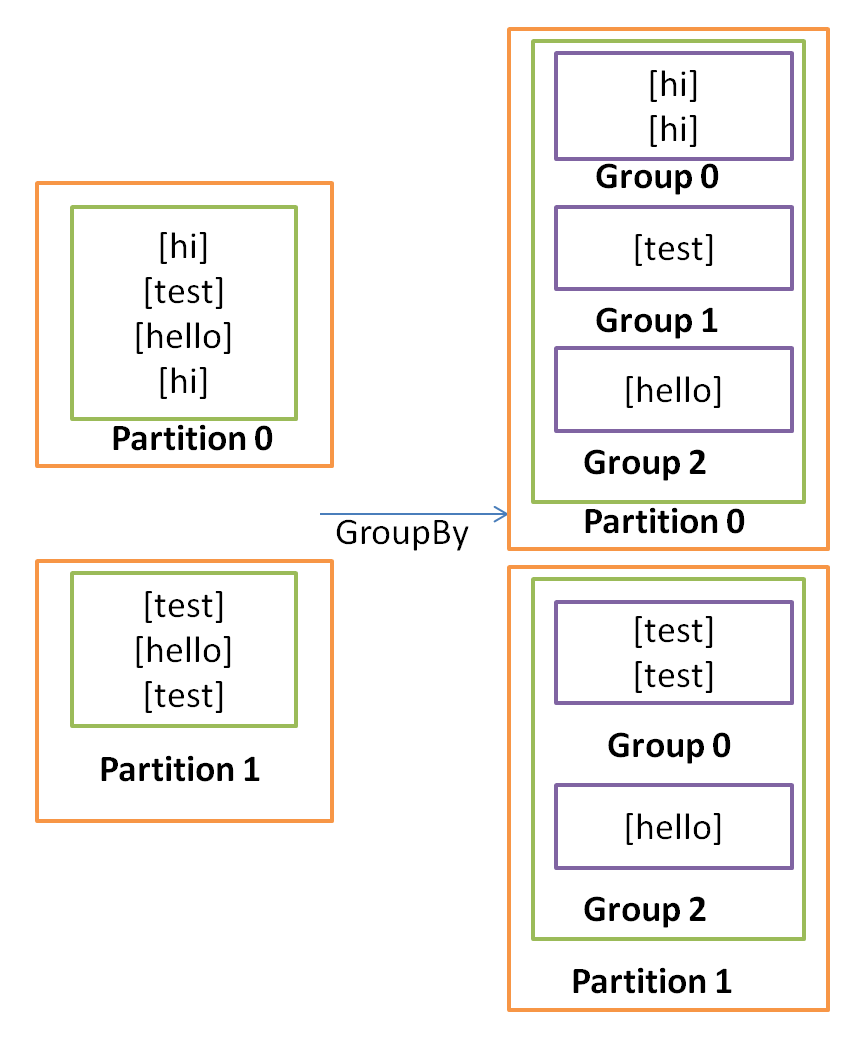
The behavior of groupBy is dependent on a position where it is used. The following behavior is possible:
- If the
groupByoperation is used before apartitionAggregate, then thepartitionAggregatewill run theaggregateon each group created within the partition. - If the
groupByoperation is used before anaggregate, the tuples of the same batch are first repartitioned into a single partition, thengroupByis applied to each single partition, and at the end it will perform theaggregateoperation on each group.