In the previous chapters, we covered the architecture of Storm, its topology, bolts, spouts, tuples, and so on. In this chapter, we are covering Trident, which is a high-level abstraction over Storm.
We are covering the following points in this chapter:
- Introducing Trident
- Understanding Trident's data model
- Writing Trident functions, filters, and projections
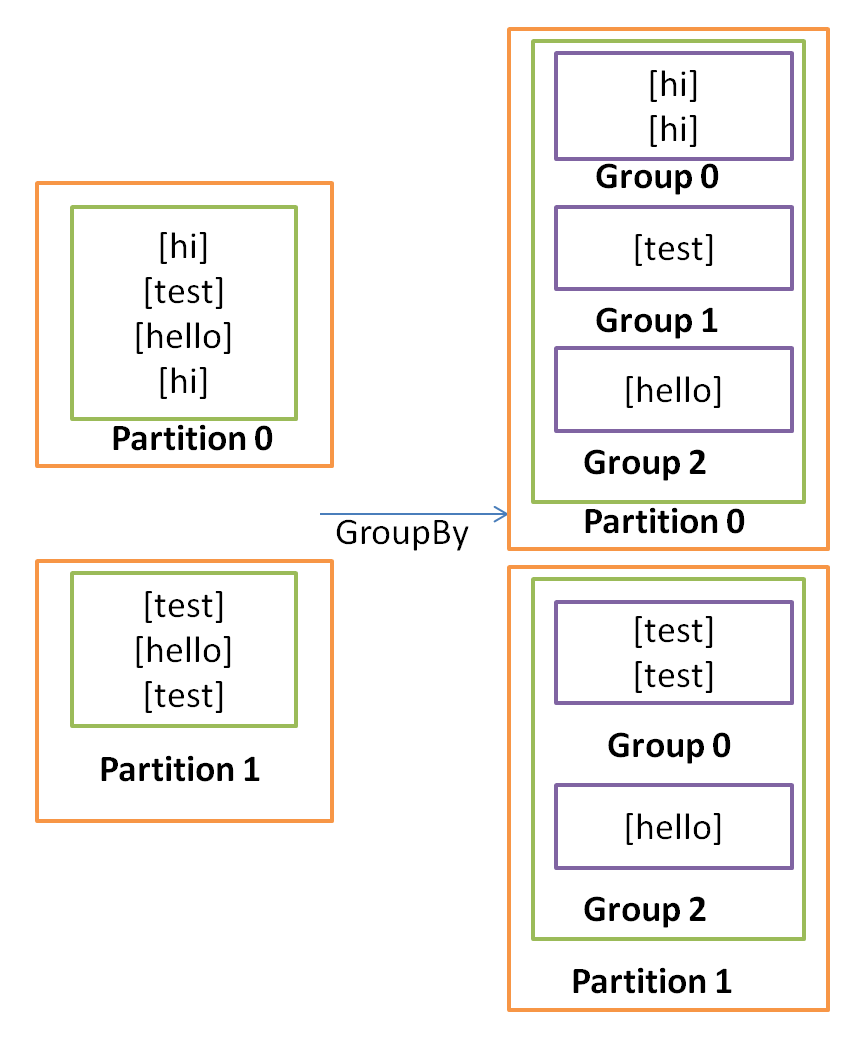
- Trident repartitioning operations
- Trident aggregators
- When to use Trident