


Hunk has the same capabilities as Splunk; as a result we can create various knowledge objects that can help us explore big data and make it more user-friendly.
Tip
A knowledge object is a configuration within Hunk that uses permissions and is controlled via the Hunk access control layer. Knowledge objects can be scoped to specific applications. Read/write permissions for them are granted to roles.
To work with knowledge objects, go to the KNOWLEDGE menu under Settings:
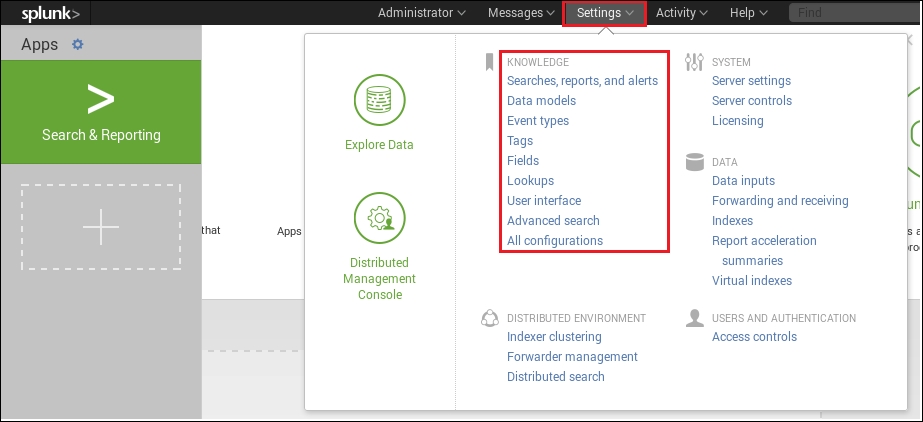
There are various knowledge objects available in Hunk. We encountered SPL, reports, dashboards, and alerts in the previous chapter. Let's expand our knowledge of Hunk and explore additional knowledge objects.
Tip
For more information about knowledge objects, see: http://docs.splunk.com/Documentation/Splunk/latest/Knowledge/WhatisSplunkknowledge.