Graph Attention Networks
Graph Attention Networks (GATs) are a theoretical improvement over GCNs. Instead of static normalization coefficients, they propose weighting factors calculated by a process called self-attention. The same process is at the core of one of the most successful deep learning architectures: the transformer, popularized by BERT and GPT-3. Introduced by Veličković et al. in 2017, GATs have become one of the most popular GNN architectures thanks to excellent out-of-the-box performance.
In this chapter, we will learn how the graph attention layer works in four steps. This is actually the perfect example for understanding how self-attention works in general. This theoretical background will allow us to implement a graph attention layer from scratch in NumPy. We will build the matrices by ourselves to understand how their values are calculated at each step.
In the last section, we’ll use a GAT on two node classification datasets: Cora, and a...
 . This approach is limiting because it only takes into account node degrees. On the other hand, the goal of the graph attention layer is to produce weighting factors that also consider the importance of
. This approach is limiting because it only takes into account node degrees. On the other hand, the goal of the graph attention layer is to produce weighting factors that also consider the importance of  , the attention score between the nodes
, the attention score between the nodes  and
and  . We can define the graph attention operator
. We can define the graph attention operator 
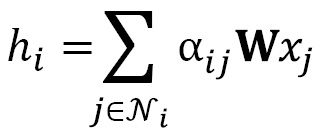
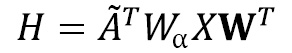
 is a matrix that stores
is a matrix that stores  .
.