


Applying supervised ML to data frame analytics
With the exception of outlier detection (covered in Chapter 10, Outlier Detection which actually is an unsupervised approach, the rest of data frame analytics uses a supervised approach. Specifically, there are two main types of problems that Elastic ML data frame analytics allows you to address:
- Regression: Used to predict a continuous numerical value (a price, a duration, a temperature, and so on)
- Classification: Used to predict whether something is of a certain class label (fraudulent transaction versus non-fraudulent, and more)
In both cases, models are built using training data to map input variables (which can be numerical or categorical) to output predictions by training decision trees. The particular implementation used by Elastic ML is a custom variant of XGBoost, an open source gradient-boosted decision tree framework that has recently gained some notoriety among data scientists for its ability to allow them to win Kaggle competitions.
The process of supervised learning
The overall process of supervised ML is very different from the unsupervised approach. In the supervised approach, you distinctly separate the training stage from the predicting stage. A very simplified version of the process looks like the following:
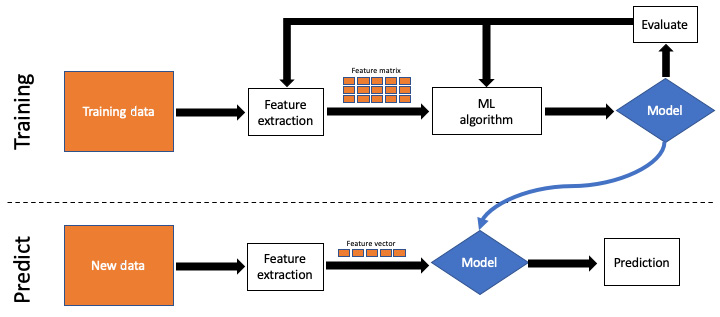
Figure 1.9 – Supervised ML process
Here, we can see that in the training phase, features are extracted out of the raw training data to create a feature matrix (also called a data frame) to feed to the ML algorithm and create the model. The model can be validated against portions of the data to see how well it did, and subsequent refinement steps could be made to adjust which features are extracted, or to refine the parameters of the ML algorithm used to improve the accuracy of the model's predictions.
Once the user decides that the model is efficacious, that model is "moved" to the prediction workflow, where it is used on new data. One at a time, a single new feature vector is inferenced against the model to form a prediction.
To get an intuitive sense of how this works, imagine a scenario in which you want to sell your house, but don't know what price to list it for. You research prior sales in your area and notice the price differentials for homes based on different factors (number of bedrooms, number of bathrooms, square footage, proximity to schools/shopping, age of home, and so on). Those factors are the "features" that are considered altogether (not individually) for every prior sale.
This corpus of historical sales is your training data. It is helpful because you know for certain how much each property sold for (and that's the thing you'd ultimately like to predict for your house). If you study this enough, you might get an intuition about how the prices of houses are driven strongly by some features (for instance, the number of bedrooms) and that other features (perhaps the age of the home) may not affect the pricing much. This is a concept called "feature importance" that will be visited again in a later chapter.
Armed with enough training data, you might have a good idea what the value of your home should be priced at, given that it is a three-bedroom, two-bath, 1,700-square-foot, 30-year-old home. In other words, you've constructed a model in your mind based on your research of comparable homes that have sold in the last year or so. If the past sales are the "training data," your home's specifications (bedrooms, bathrooms, and so on) are the feature vectors that will define the expected price, given your "model" that you've learned.
Your simple mental model is obviously not as rigorous as one that could be constructed with regression analysis using ML using dozens of relevant input features, but this simple analogy hopefully cements the idea of the process that is followed in learning from prior, known situations, and then applying that knowledge to a present, novel situation.