


Overview of the Transformer architecture
Transformer models have received immense interest because of their effectiveness in an enormous range of NLP problems, from text classification to text generation. The attention mechanism is an important part of these models and plays a very crucial role. Before Transformer models, the attention mechanism was proposed as a helper for improving conventional DL models such as RNNs. To have a good understanding of Transformers and their impact on the NLP, we will first study the attention mechanism.
Attention mechanism
One of the first variations of the attention mechanism was proposed by Bahdanau et al. (2015). This mechanism is based on the fact that RNN-based models such as GRUs or LSTMs have an information bottleneck on tasks such as Neural Machine Translation (NMT). These encoder-decoder-based models get the input in the form of a token-id and process it in a recurrent fashion (encoder). Afterward, the processed intermediate representation is fed into another recurrent unit (decoder) to extract the results. This avalanche-like information is like a rolling ball that consumes all the information, and rolling it out is hard for the decoder part because the decoder part does not see all the dependencies and only gets the intermediate representation (context vector) as an input.
To align this mechanism, Bahdanau proposed an attention mechanism to use weights on intermediate hidden values. These weights align the amount of attention a model must pay to input in each decoding step. Such wonderful guidance assists models in specific tasks such as NMT, which is a many-to-many task. A diagram of a typical attention mechanism is provided here:
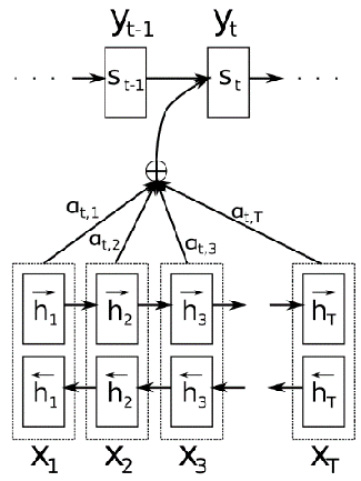
Figure 1.12 – Attention mechanism
Different attention mechanisms have been proposed with different improvements. Additive, multiplicative, general, and dot-product attention appear within the family of these mechanisms. The latter, which is a modified version with a scaling parameter, is noted as scaled dot-product attention. This specific attention type is the foundation of Transformers models and is called a multi-head attention mechanism. Additive attention is also what was introduced earlier as a notable change in NMT tasks. You can see an overview of the different types of attention mechanisms here:
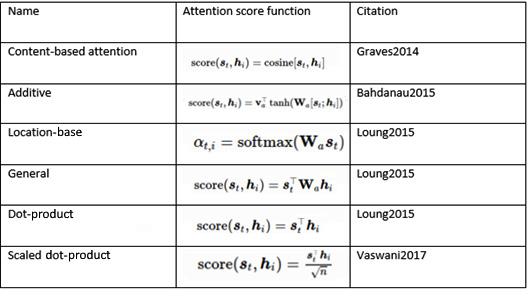
Table 2 – Types of attention mechanisms (Image inspired from https://lilianweng.github.io/lil-log/2018/06/24/attention-attention.html)
Since attention mechanisms are not specific to NLP, they are also used in different use cases in various fields, from computer vision to speech recognition. The following screenshot shows a visualization of a multimodal approach trained for neural image captioning (K Xu et al., Show, attend and tell: Neural image caption generation with visual attention, 2015):

Figure 1.13 – Attention mechanism in computer vision
The multi-head attention mechanism that is shown in the following diagram is an essential part of the Transformer architecture:
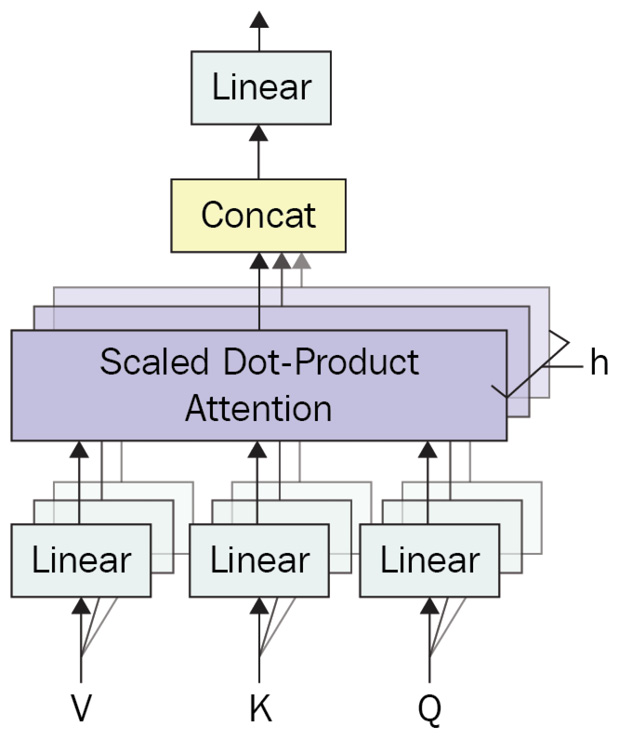
Figure 1.14 – Multi-head attention mechanism
Next, let's understand multi-head attention mechanisms.
Multi-head attention mechanisms
Before jumping into scaled dot-product attention mechanisms, it's better to get a good understanding of self-attention. Self-attention, as shown in Figure 1.15, is a basic form of a scaled self-attention mechanism. This mechanism uses an input matrix shown as X and produces an attention score between various items in X. We see X as a 3x4 matrix where 3 represents the number of tokens and 4 presents the embedding size. Q from Figure 1.15 is also known as the query, K is known as the key, and V is noted as the value. Three types of matrices shown as theta, phi, and g are multiplied by X before producing Q, K, and V. The multiplied result between query (Q) and key (K) yields an attention score matrix. This can also be seen as a database where we use the query and keys in order to find out how much various items are related in terms of numeric evaluation. Multiplication of the attention score and the V matrix produces the final result of this type of attention mechanism. The main reason for it being called self-attention is because of its unified input X; Q, K, and V are computed from X. You can see all this depicted in the following diagram:
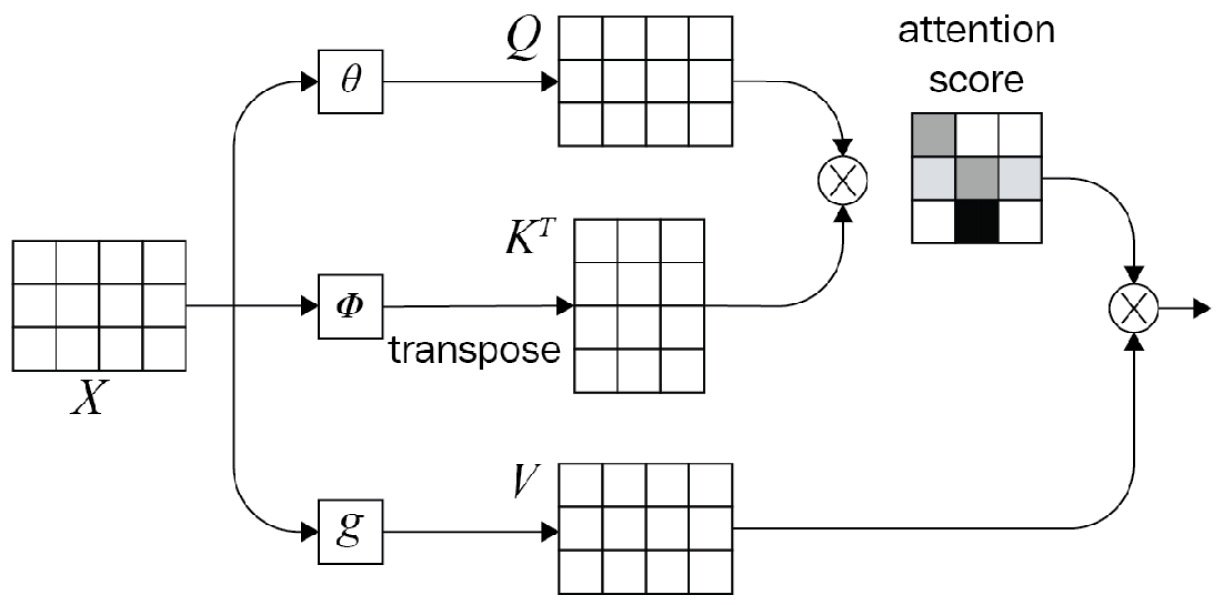
Figure 1.15 – Mathematical representation for the attention mechanism (Image inspired from https://blogs.oracle.com/datascience/multi-head-self-attention-in-nlp)
A scaled dot-product attention mechanism is very similar to a self-attention (dot-product) mechanism except it uses a scaling factor. The multi-head part, on the other hand, ensures the model is capable of looking at various aspects of input at all levels. Transformer models attend to encoder annotations and the hidden values from past layers. The architecture of the Transformer model does not have a recurrent step-by-step flow; instead, it uses positional encoding in order to have information about the position of each token in the input sequence. The concatenated values of the embeddings (randomly initialized) and the fixed values of positional encoding are the input fed into the layers in the first encoder part and are propagated through the architecture, as illustrated in the following diagram:
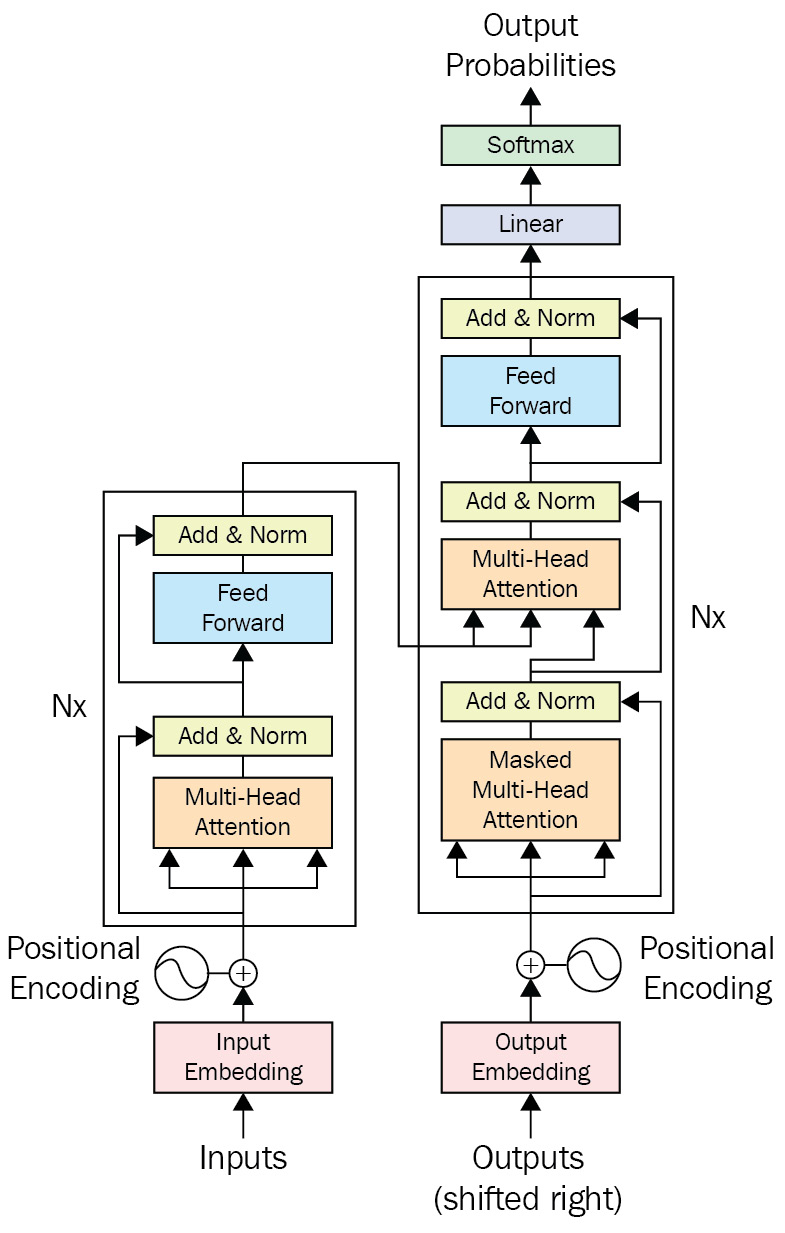
Figure 1.16 – A Transformer
The positional information is obtained by evaluating sine and cosine waves at different frequencies. An example of positional encoding is visualized in the following screenshot:
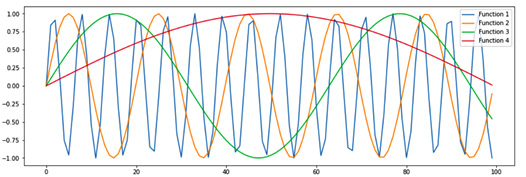
Figure 1.17 – Positional encoding (Image inspired from http://jalammar.github.io/illustrated-Transformer/)
A good example of performance on the Transformer architecture and the scaled dot-product attention mechanism is given in the following popular screenshot:
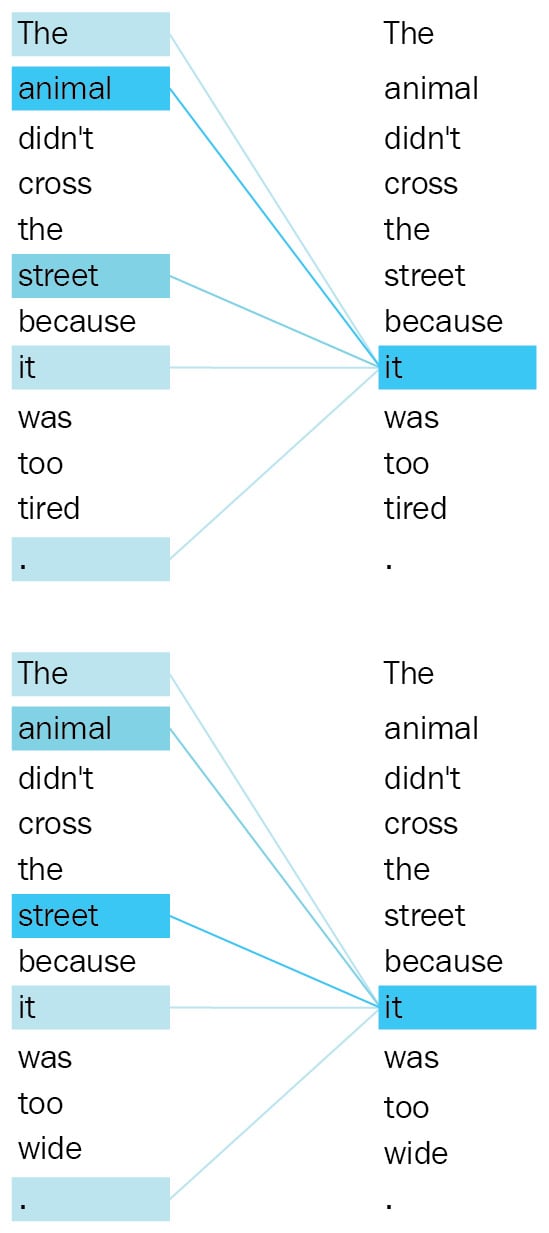
Figure 1.18 – Attention mapping for Transformers (Image inspired from https://ai.googleblog.com/2017/08/Transformer-novel-neural-network.html)
The word it refers to different entities in different contexts, as is seen from the preceding screenshot. Another improvement made by using a Transformer architecture is in parallelism. Conventional sequential recurrent models such as LSTMs and GRUs do not have such capabilities because they process the input token by token. Feed-forward layers, on the other hand, speed up a bit more because single matrix multiplication is far faster than a recurrent unit. Stacks of multi-head attention layers gain a better understanding of complex sentences. A good visual example of a multi-head attention mechanism is shown in the following screenshot:
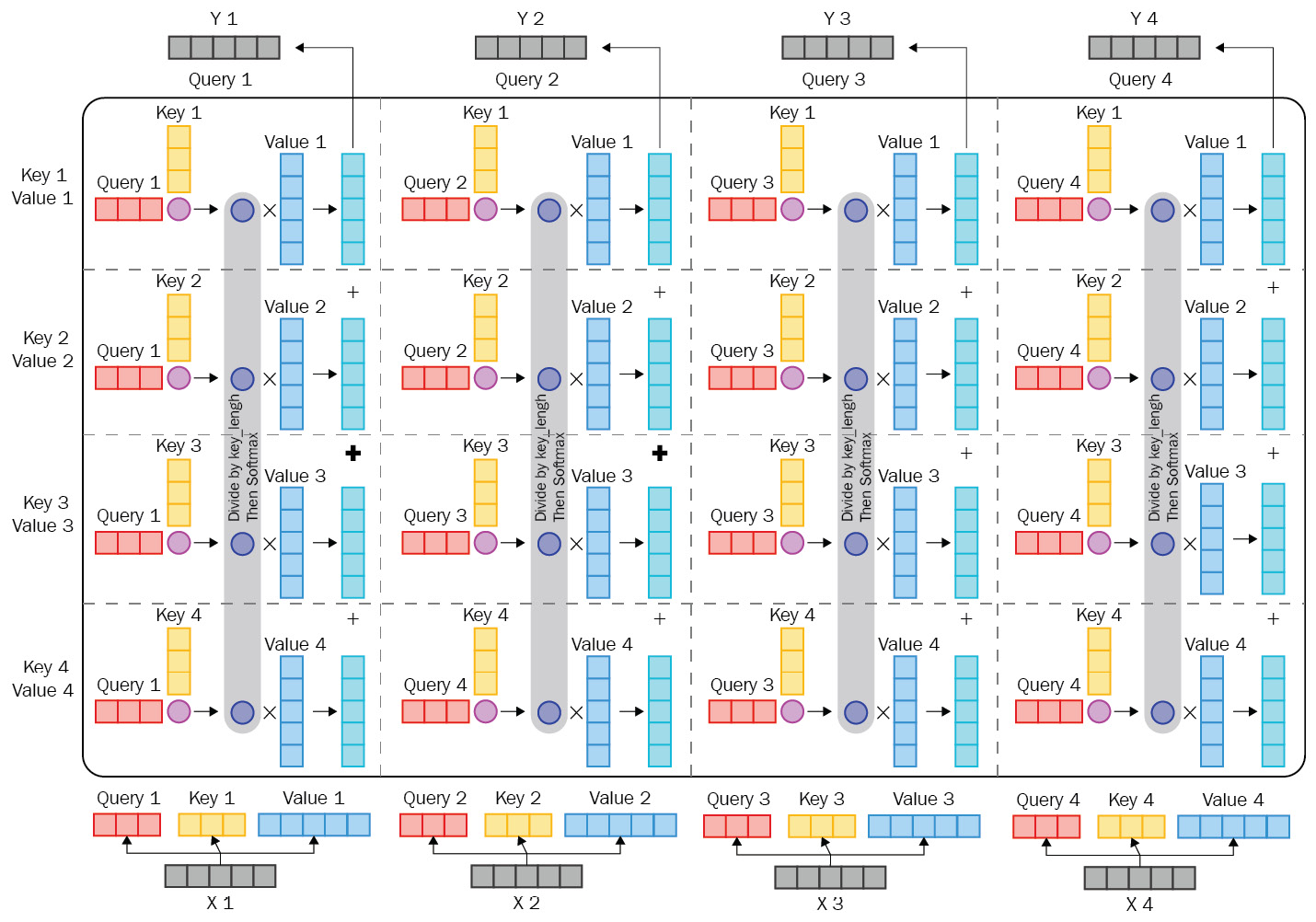
Figure 1.19 – Multi-head attention mechanism (Image inspired from https://imgur.com/gallery/FBQqrxw)
On the decoder side of the attention mechanism, a very similar approach to the encoder is utilized with small modifications. A multi-head attention mechanism is the same, but the output of the encoder stack is also used. This encoding is given to each decoder stack in the second multi-head attention layer. This little modification introduces the output of the encoder stack while decoding. This modification lets the model be aware of the encoder output while decoding and at the same time help it during training to have a better gradient flow over various layers. The final softmax layer at the end of the decoder layer is used to provide outputs for various use cases such as NMT, for which the original Transformer architecture was introduced.
This architecture has two inputs, noted as inputs and outputs (shifted right). One is always present (the inputs) in both training and inference, while the other is just present in training and in inference, which is produced by the model. The reason we do not use model predictions in inference is to stop the model from going too wrong by itself. But what does it mean? Imagine a neural translation model trying to translate a sentence from English to French—at each step, it makes a prediction for a word, and it uses that predicted word to predict the next one. But if it goes wrong at some step, all the following predictions will be wrong too. To stop the model from going wrong like this, we provide the correct words as a shifted-right version.
A visual example of a Transformer model is given in the following diagram. It shows a Transformer model with two encoders and two decoder layers. The Add & Normalize layer from this diagram adds and normalizes the input it takes from the Feed Forward layer:
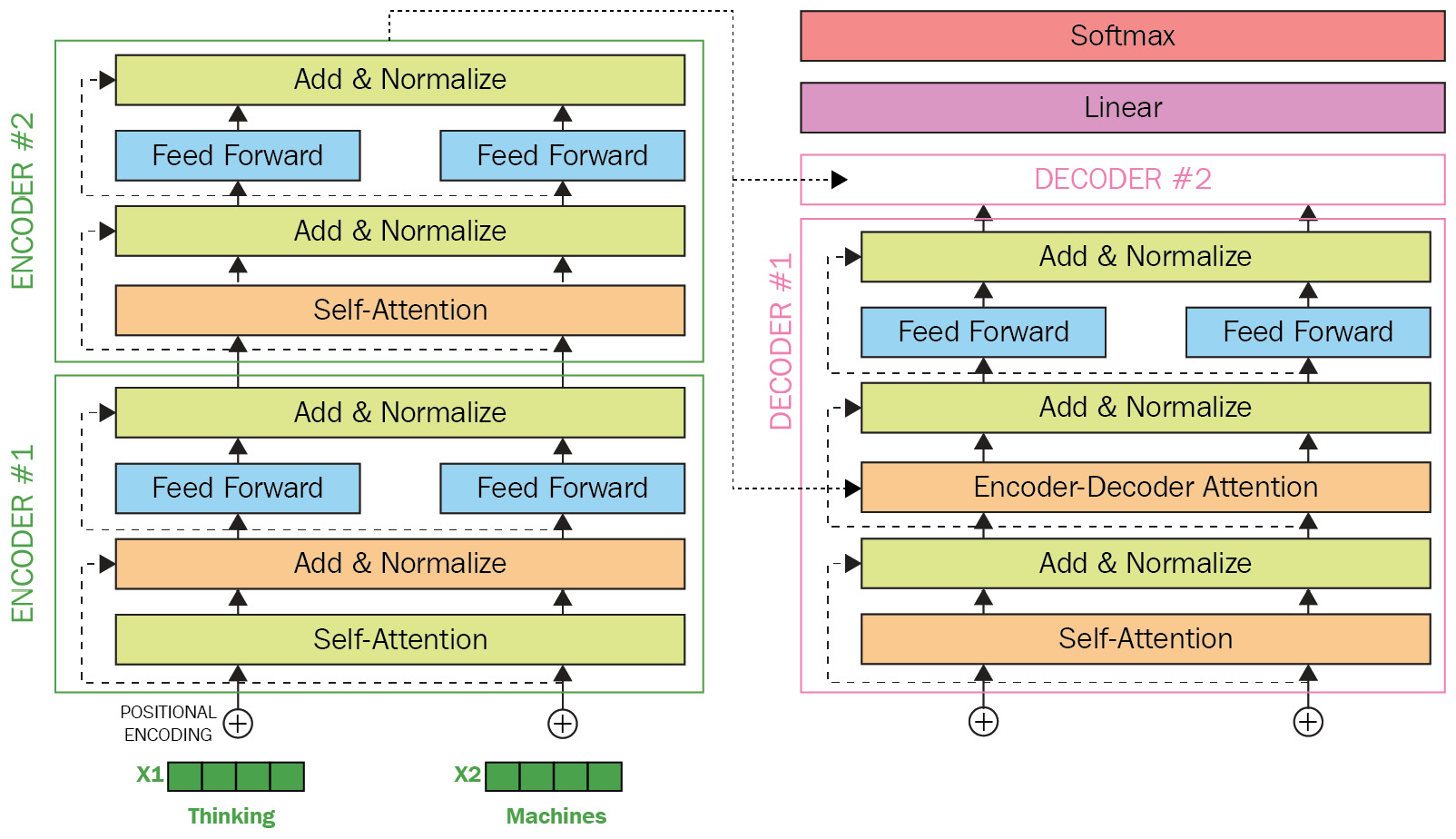
Figure 1.20 – Transformer model (Image inspired from http://jalammar.github.io/illustrated-Transformer/)
Another major improvement that is used by a Transformer-based architecture is based on a simple universal text-compression scheme to prevent unseen tokens on the input side. This approach, which takes place by using different methods such as byte-pair encoding and sentence-piece encoding, improves a Transformer's performance in dealing with unseen tokens. It also guides the model when the model encounters morphologically close tokens. Such tokens were unseen in the past and are rarely used in the training, and yet, an inference might be seen. In some cases, chunks of it are seen in training; the latter happens in the case of morphologically rich languages such as Turkish, German, Czech, and Latvian. For example, a model might see the word training but not trainings. In such cases, it can tokenize trainings as training+s. These two are commonly seen when we look at them as two parts.
Transformer-based models have quite common characteristics—for example, they are all based on this original architecture with differences in which steps they use and don't use. In some cases, minor differences are made—for example, improvements to the multi-head attention mechanism taking place.