


Tabular Learning and the Bellman Equation
In the previous chapter, you became acquainted with your first reinforcement learning (RL) algorithm, the cross-entropy method, along with its strengths and weaknesses. In this new part of the book, we will look at another group of methods that has much more flexibility and power: Q-learning. This chapter will establish the required background shared by those methods.
We will also revisit the FrozenLake environment and explore how new concepts fit with this environment and help us to address issues of its uncertainty.
In this chapter, we will:
- Review the value of the state and value of the action, and learn how to calculate them in simple cases
- Talk about the Bellman equation and how it establishes the optimal policy if we know the values
- Discuss the value iteration method and try it on the FrozenLake environment
- Do the same for the Q-learning method
Despite the simplicity of the environments in this chapter...
 , where rt is the local reward obtained at step t of the episode.
, where rt is the local reward obtained at step t of the episode. or not (the undiscounted case corresponds to
or not (the undiscounted case corresponds to  ); it's up to us how to define it. The value is always calculated in terms of some policy that our agent follows. To illustrate this, let's consider a very simple environment with three states:
); it's up to us how to define it. The value is always calculated in terms of some policy that our agent follows. To illustrate this, let's consider a very simple environment with three states:
 . So, to choose the best possible action, the agent needs to calculate the resulting values for every action and choose the maximum possible outcome. In other words,
. So, to choose the best possible action, the agent needs to calculate the resulting values for every action and choose the maximum possible outcome. In other words,  . If we are using the...
. If we are using the...


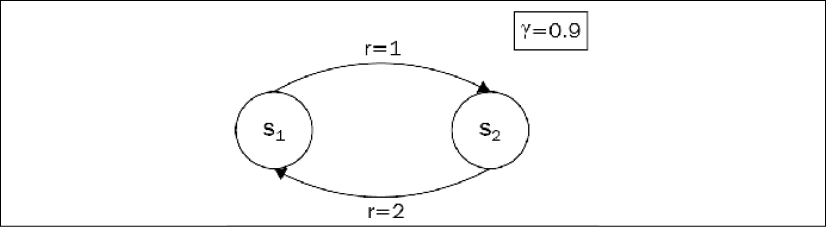
 . To deal with this infinity
. To deal with this infinity . Now, the question is, what are the values for both the states? The answer is not very complicated, in fact. Every transition from s1 to s2 gives us a reward of 1 and every back...
. Now, the question is, what are the values for both the states? The answer is not very complicated, in fact. Every transition from s1 to s2 gives us a reward of 1 and every back...