


Statistical Significance Testing
Another piece of analysis that is useful in data analysis is statistical significance testing. Often times, an analyst is interested in comparing the statistical properties of two groups, or perhaps just one group before and after a change. Of course, the difference between these two groups may just be due to chance.
An example of where this comes up is in marketing A/B tests. Companies will often test two different types of landing pages for a product and measure the click-through rate (CTR). You may find that the CTR for variation A of the landing page is 10%, and the CTR for variation B is 11%. So, does that mean that variation B is 10% better than A, or is this just a result of day-to-day variance? Statistical testing helps us to determine just that.
In statistical testing, there are a couple of major parts you need to have (Figure 1.32). First, we have the test statistic we are examining. It may be a proportion, an average, the difference between two groups, or a distribution. The next necessary part is a null hypothesis, which is the idea that the results observed are the product of chance. You will then need an alternative hypothesis, which is the idea that the results seen cannot be explained by chance alone. Finally, a test needs a significance level, which is the value the test statistic needs to take before it is decided that the null hypothesis cannot explain the difference. All statistical significance tests have these four aspects, and it is simply a matter of how these components are calculated that differentiate significance tests:
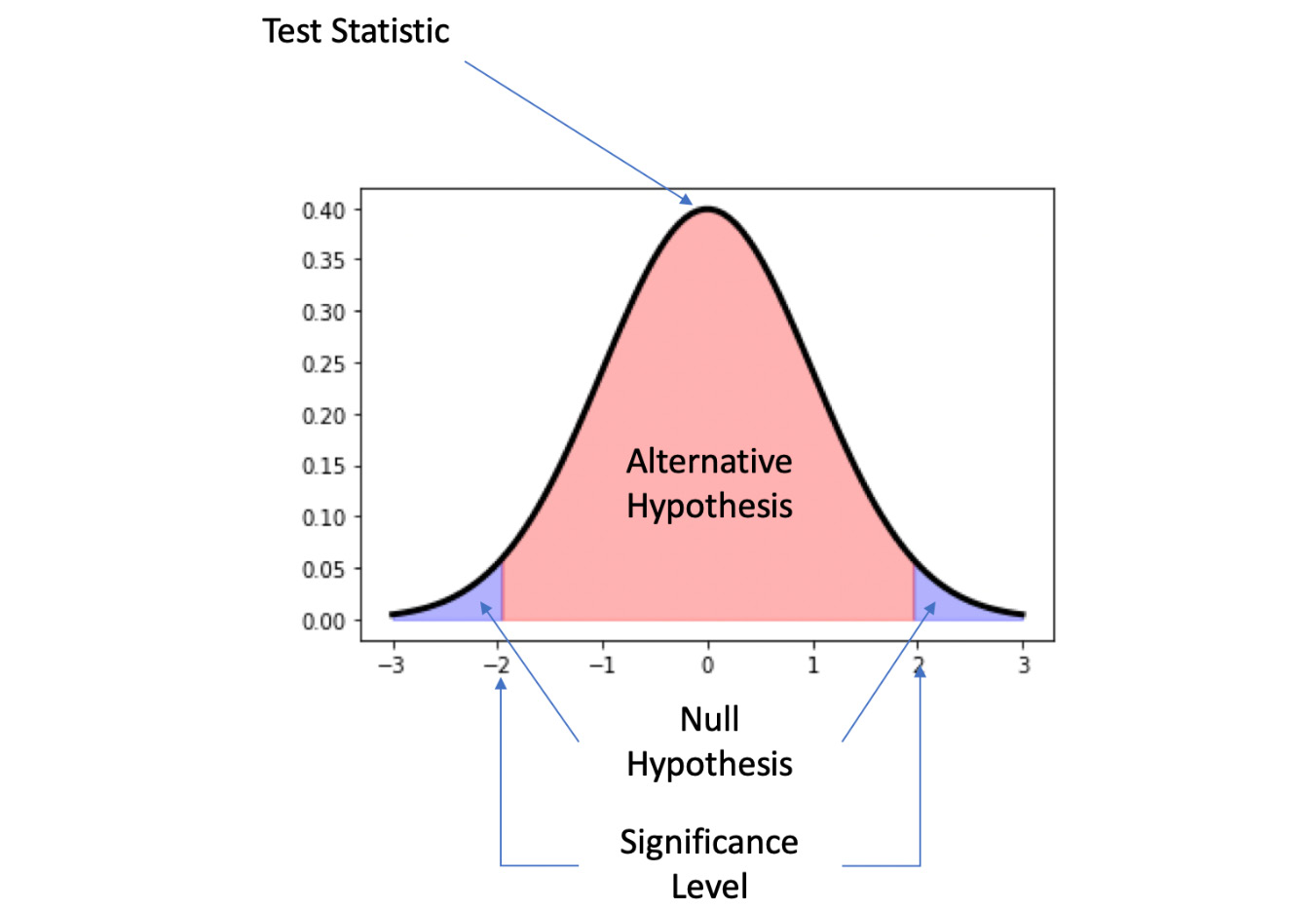
Figure 1.32: Parts of statistical significance testing
Common Statistical Significance Tests
Some common statistical significance tests include the following:
- Two-sample Z-test: A test to determine whether the averages of the two samples are different. This test assumes that both samples are drawn from a normal distribution with a known population standard deviation.
- Two-sample T-test: A test to determine whether the average of two samples is different when either the sample set is too small (that is, fewer than 30 data points per sample), or if the population standard deviation is unknown. The two samples are also generally drawn from distributions assumed to be normal.
- Pearson's Chi-Squared Test: A test to determine whether the distribution of data points to categories is different than what would be expected due to chance. This is the primary test for determining whether the proportions in tests, such as those in an A/B test, are beyond what would be expected from chance.
Note
To learn more about statistical significance, please refer to a statistics textbook, such as Statistics by David Freedman, Robert Pisani, and Roger Purves.