


Distributed computing
Scalability refers to a system's ability to adapt to an increase in load without degrading performance. There are two ways to scale a system – vertically and horizontally. Vertical scaling refers to using a bigger instance type with more compute horsepower, while horizontal scaling refers to using more of the same node type to distribute the load.
In general terms, a process is an instance of a program that's being executed. It consists of several activities and each activity is a series of tasks. In the big data space, there is a lot of data to crunch, so there's a need to improve computing speeds by increasing the level of parallelization. There are several multiprocessor architectures, and it is important to understand the nuances to pick linearly scalable architectures that can not only accommodate present volumes but also future increases.
SMP and MPP computing
Both symmetric multi-processing (SMP) and MPP are multiprocessor systems.
As data volume grows, SMP architectures transition to MPP ones. MPP is designed to handle multiple operations simultaneously by several processing units. Each processing unit works independently with its resources, including its operating system and dedicated memory. Let's take a closer look:
- SMP: All the processing units share the same resources (operating system, memory, and disk storage) and are connected on a system bus. This becomes the choke factor of the architectures scaling linearly:
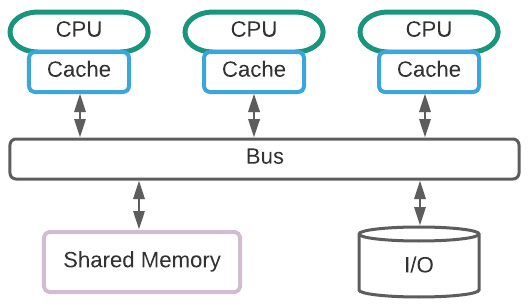
Figure 1.13 – SMP
- MPP: Each processor has its own set of resources and is fully independent and isolated from other processors. Examples of popular MPP databases include Teradata, GreenPlum, Vertica, AWS Redshift, and many more:
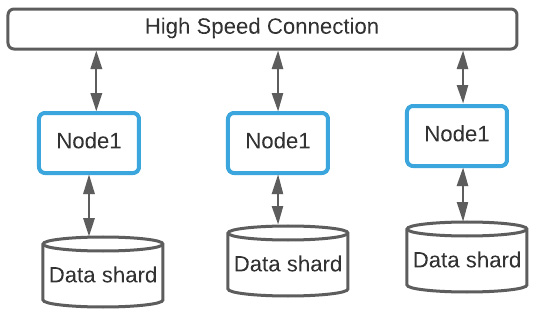
Figure 1.14 – MPP
In the next section, we'll explore Hadoop and Spark, which are newer entrants to the space, and the map/reduce and Resilient Distributed Datasets (RDDs) concepts, which mimic the parallelism constructs of MPP databases.
Parallel and distributed computing
Advances in distributed computing have pushed the envelope on compute speeds and made this process possible. It is important to note that parallel processing is a type of distributed processing. Let's take a closer look:
- Parallel Processing:
In parallel processing, all the processors have access to a single shared memory (https://en.wikipedia.org/wiki/Shared_memory_architecture) instead of having to exchange information by passing messages between the processors:
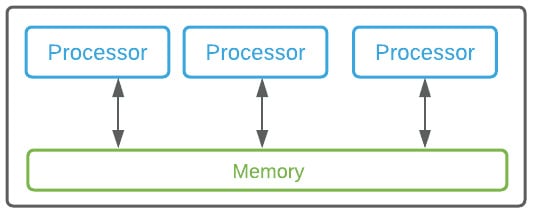
Figure 1.15 – Parallel processing
- Distributed Processing:
In distributed processing, the processors have access to their own memory pool:

Figure 1.16 – Distributed computing
The two most popular distributed architectures are Hadoop and Spark. Let's look at them in more detail.
Hadoop
Hadoop is an Apache open source project that started as a Yahoo! project in 2006. It promises to provide an inexpensive, reliable, and scalable framework. Several distributions, such as Cloudera, Hortonworks, MapR, and EMR, have offered packaging variations. It is compatible with many types of hardware where it runs as an appliance. It works with scalable distributed filesystems such as S3, HFTP FS, and HDFS with multiple replications on commodity-grade hardware and has a service-oriented architecture with many open source components.
It has a master-slave architecture that follows the map/reduce model. The three main components of the Hadoop framework are HDFS for storage, YARN for resource management, and Map Reduce as the application layer. The HDFS data is broken into blocks, replicated a certain number of times, and sent to worker nodes where they are processed in parallel. It consists of a series of map and reduce jobs. NameNode keeps track of everything in the cluster. As the resource manager, YARN allocates the resources in a multi-tenant environment. JobTracker and TaskTracker monitor the progress of a job. All the results from the MapReduce stage are then aggregated and written back to disk in HDFS:

Figure 1.17 – Hadoop map/reduce architecture
Spark
Spark is an Apache open source project that started in 2012, at AMPLab (https://amplab.cs.berkeley.edu/) at UC Berkeley. It was written in Scala and provides support for the Scala, Java, Python, R, and SQL languages. It has connectors for several disparate providers/consumers. In Spark lingo, a job is broken into several stages and each stage is broken into several tasks that are executed by executors on cores. Data is broken into partitions that are processed in parallel on worker node cores. So, being able to partition effectively and having sufficient cores is what enables Spark to be horizontally scalable:

Figure 1.18 – Spark distributed computing architecture
Spark is a favorite tool in the world of big data, not only for its speed but also its multifaceted capabilities. This makes it favorable for a wide variety of data personas working on a wide range of use cases. It is no wonder that it is regarded as a Swiss Army knife for data processing:

Figure 1.19 – Spark is a Swiss Army knife in the world of data
Hadoop versus Spark
Spark is ~100x faster in-memory than Hadoop. This is on account of more disk operations in Hadoop, where each map and reduce operation in a job chain goes to disk. Spark, on the other hand, processes and retains data in memory for subsequent steps in a Directed Acyclic Graph (DAG). Spark processes data in RAM using a concept known as a Resilient Distributed Dataset (RDD), which is immutable. So, every transformation is a node in the DAG that is lazily evaluated when it encounters an explicit action. Although Spark is a standalone technology, it was also packaged with the Hadoop ecosystem to provide an alternative to Map Reduce. Hadoop is losing favor and is on the decline, whereas Spark continues to be an industry favorite.