

Until now, in this book, we have been mostly using convolutional neural networks (CNNs) for classification. Classification classifies the whole image into one of the classes with respect to the entity having the maximum probability of detection in the image. But what if there is not one, but multiple entities of interest and we want to have the image associated with all of them? One way to do this is to use tags instead of classes, where these tags are all classes of the penultimate Softmax classification layer with probability above a given threshold. However, the probability of detection here varies widely by size and placement of entity, and from the following image, we can actually say, How confident is the model that the identified entity is the one that is claimed? What if we are very confident that there is an...

The differences between object detection and image classification
Let's take another example. You are watching the movie 101 Dalmatians, and you want to know how many Dalmatians you can actually count in a given movie scene from that movie. Image Classification could, at best, tell you that there is at least one dog or one Dalmatian (depending upon which level you have trained your classifier for), but not exactly how many of them there are.
Another issue with classification-based models is that they do not tell you where the identified entity in the image is. Many times, this is very important. Say, for example, you saw your neighbor's dog playing with him (Person) and his cat. You took a snap of them and wanted to extract the image of the dog from there to search on the web for its breed or similar dogs like it. The only problem here is that searching...
Traditional, nonCNN approaches to object detection
Libraries such as OpenCV and some others saw rapid inclusion in the software bundles for Smartphones, Robotic projects, and many others, to provide detection capabilities of specific objects (face, smile, and so on), and Computer Vision like benefits, though with some constraints even before the prolific adoption of CNN.
CNN-based research in this area of object detection and Instance Segmentation provided many advancements and performance enhancements to this field, not only enabling large-scale deployment of these systems but also opening avenues for many new solutions. But before we plan to jump into CNN based advancements, it will be a good idea to understand how the challenges cited in the earlier section were answered to make object detection possible in the first place (even with all the constraints), and then we will logically...
Let's take another example. You are watching the movie 101 Dalmatians, and you want to know how many Dalmatians you can actually count in a given movie scene from that movie. Image Classification could, at best, tell you that there is at least one dog or one Dalmatian (depending upon which level you have trained your classifier for), but not exactly how many of them there are.
Another issue with classification-based models is that they do not tell you where the identified entity in the image is. Many times, this is very important. Say, for example, you saw your neighbor's dog playing with him (Person) and his cat. You took a snap of them and wanted to extract the image of the dog from there to search on the web for its breed or similar dogs like it. The only problem here is that searching the whole image might not work, and without identifying individual objects from the image, you have to do the cut-extract-search job manually...
Libraries such as OpenCV and some others saw rapid inclusion in the software bundles for Smartphones, Robotic projects, and many others, to provide detection capabilities of specific objects (face, smile, and so on), and Computer Vision like benefits, though with some constraints even before the prolific adoption of CNN.
CNN-based research in this area of object detection and Instance Segmentation provided many advancements and performance enhancements to this field, not only enabling large-scale deployment of these systems but also opening avenues for many new solutions. But before we plan to jump into CNN based advancements, it will be a good idea to understand how the challenges cited in the earlier section were answered to make object detection possible in the first place (even with all the constraints), and then we will logically start our discussion about the different researchers and the application of CNN to solve other problems that...
In the 'Why is object detection much more challenging than image classification?' section, we used a non-CNN method to draw region proposals and CNN for classification, and we realized that this is not going to work well because the regions generated and fed into CNN were not optimal. R-CNN or regions with CNN features, as the name suggests, flips that example completely and use CNN to generate features that are classified using a (non-CNN) technique called SVM (Support Vector Machines)
R-CNN uses the sliding window method (much like we discussed earlier, taking some L x W and stride) to generate around 2,000 regions of interest, and then it converts them into features for classification using CNN. Remember what we discussed in the transfer learning chapter—the last flattened layer (before the classification or softmax layer) can be extracted to transfer learning from models trained on generalistic data, and further train them (often requiring much less data...
Fast R-CNN, or Fast Region-based CNN method, is an improvement over the previously covered R-CNN. To be precise about the improvement statistics, as compared to R-CNN, it is:
- 9x faster in training
- 213x faster at scoring/servicing/testing (0.3s per image processing), ignoring the time spent on region proposals
- Has higher mAP of 66% on the PASCAL VOC 2012 dataset
Where R-CNN uses a smaller (five-layer) CNN, Fast R-CNN uses the deeper VGG16 network, which accounts for its improved accuracy. Also, R-CNN is slow because it performs a ConvNet forward pass for each object proposal without sharing computation:
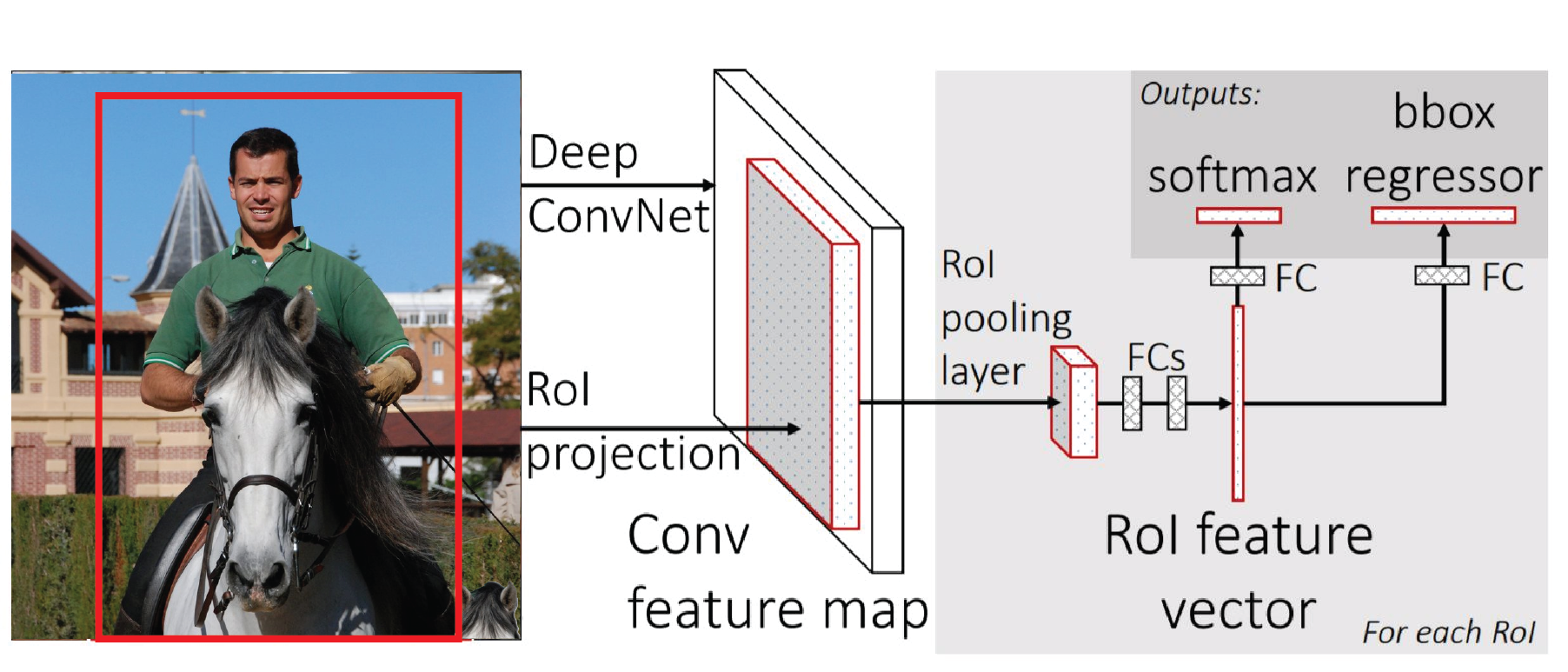
Fast R-CNN: Working
In Fast R-CNN, the deep VGG16 CNN provides essential computations for all the stages, namely:
- Region of Interest (RoI) computation
- Classification Objects (or background) for the region contents
- Regression for enhancing the bounding box
The input to the CNN, in this case, is not raw (candidate) regions from the image, but the (complete) actual image...
We saw in the earlier section that Fast R-CNN brought down the time required for scoring (testing) images drastically, but the reduction ignored the time required for generating Region Proposals, which use a separate mechanism (though pulling from the convolution map from CNN) and continue proving a bottleneck. Also, we observed that though all three challenges were resolved using the common features from convolution-map in Fast R-CNN, they were using different mechanisms/models.
Faster R-CNN improves upon these drawbacks and proposes the concept of Region Proposal Networks (RPNs), bringing down the scoring (testing) time to 0.2 seconds per image, even including time for Region Proposals.
Note
Fast R-CNN was doing the scoring (testing) in 0.3 seconds per image, that too excluding the time required for the process equivalent to Region Proposal.

Faster R-CNN: Working - The Region Proposal Networking acting as Attention Mechanism
As shown in...
Faster R-CNN is state-of-the-art stuff in object detection today. But there are problems overlapping the area of object detection that Faster R-CNN cannot solve effectively, which is where Mask R-CNN, an evolution of Faster R-CNN can help.
This section introduces the concept of instance segmentation, which is a combination of the standard object detection problem as described in this chapter, and the challenge of semantic segmentation.
Note
In semantic segmentation, as applied to images, the goal is to classify each pixel into a fixed set of categories without differentiating object instances.
Remember our example of counting the number of dogs in the image in the intuition section? We were able to count the number of dogs easily, because they were very much apart, with no overlap, so essentially just counting the number of objects did the job. Now, take the following image, for instance, and count the number of tomatoes using object detection. It...
It's now time to put the things that we've learned into practice. We'll use the COCO dataset and its API for the data, and use Facebook Research's Detectron project (link in References), which provides the Python implementation of many of the previously discussed techniques under an Apache 2.0 license. The code works with Python2 and Caffe2, so we'll need a virtual environment with the given configuration.
The rest of the chapter is locked
You have been reading a chapter from
Practical Convolutional Neural NetworksPublished in: Feb 2018Publisher: PacktISBN-13: 9781788392303
Register for a free Packt account to unlock a world of extra content!
A free Packt account unlocks extra newsletters, articles, discounted offers, and much more. Start advancing your knowledge today.
undefined
Unlock this book and the full library FREE for 7 days
Get unlimited access to 7000+ expert-authored eBooks and videos courses covering every tech area you can think of
Renews at $15.99/month. Cancel anytime