

In this chapter, will introduce the ImageNet image database and also cover the architectures of the following popular CNN models:
- LeNet
- AlexNet
- VGG
- GoogLeNet
- ResNet

In this chapter, will introduce the ImageNet image database and also cover the architectures of the following popular CNN models:
ImageNet is a database of over 15 million hand-labeled, high-resolution images in roughly 22,000 categories. This database is organized just like the WordNet hierarchy, where each concept is also called a synset (that is, synonym set). Each synset is a node in the ImageNet hierarchy. Each node has more than 500 images.
The ImageNet Large Scale Visual Recognition Challenge (ILSVRC) was founded in 2010 to improve state-of-the-art technology for object detection and image classification on a large scale:

Following this overview of ImageNet, we will now take a look at various CNN model architectures.
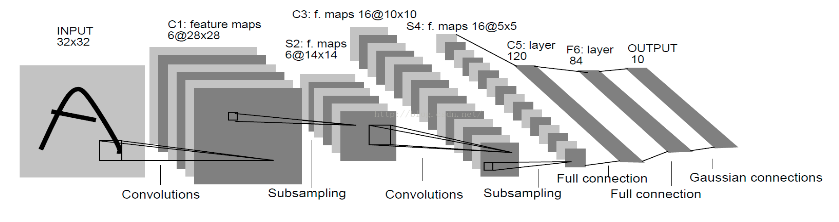
In 2010, a challenge from ImageNet (known as ILSVRC 2010) came out with a CNN architecture, LeNet 5, built by Yann Lecun. This network takes a 32 x 32 image as input, which goes to the convolution layers (C1) and then to the subsampling layer (S2). Today, the subsampling layer is replaced by a pooling layer. Then, there is another sequence of convolution layers (C3) followed by a pooling (that is, subsampling) layer (S4). Finally, there are three fully connected layers, including the OUTPUT layer at the end. This network was used for zip code recognition in post offices. Since then, every year various CNN architectures were introduced with the help of this competition:
Therefore, we can conclude the following points:
The first breakthrough in the architecture of CNN came in the year 2012. This award-winning CNN architecture is called AlexNet. It was developed at the University of Toronto by Alex Krizhevsky and his professor, Jeffry Hinton.
In the first run, a ReLU activation function and a dropout of 0.5 were used in this network to fight overfitting. As we can see in the following image, there is a normalization layer used in the architecture, but this is not used in practice anymore as it used heavy data augmentation. AlexNet is still used today even though there are more accurate networks available, because of its relative simple structure and small depth. It is widely used in computer vision:

AlexNet is trained on the ImageNet database using two separate GPUs, possibly due to processing limitations with inter-GPU connections at the time, as shown in the...
The runner-up in the 2014 ImageNet challenge was VGGNet from the visual geometric group at Oxford University. This convolutional neural network is a simple and elegant architecture with a 7.3% error rate. It has two versions: VGG16 and VGG19.
VGG16 is a 16-layer neural network, not counting the max pooling layer and the softmax layer. Hence, it is known as VGG16. VGG19 consists of 19 layers. A pre-trained model is available in Keras for both Theano and TensorFlow backends.
The key design consideration here is depth. Increases in the depth of the network were achieved by adding more convolution layers, and it was done due to the small 3 x 3 convolution filters in all the layers. The default input size of an image for this model is 224 x 224 x 3. The image is passed through a stack of convolution layers with a stride of 1 pixel and padding of 1. It uses 3 x 3...
In 2014, ILSVRC, Google published its own network known as GoogLeNet. Its performance is a little better than VGGNet; GoogLeNet's performance is 6.7% compared to VGGNet's performance of 7.3%. The main attractive feature of GoogLeNet is that it runs very fast due to the introduction of a new concept called inception module, thus reducing the number of parameters to only 5 million; that's 12 times less than AlexNet. It has lower memory use and lower power use too.
It has 22 layers, so it is a very deep network. Adding more layers increases the number of parameters and it is likely that the network overfits. There will be more computation, because a linear increase in filters results in a quadratic increase in computation. So, the designers use the inception module and GAP. The fully connected layer at the end of the network is replaced...
ImageNet is a database of over 15 million hand-labeled, high-resolution images in roughly 22,000 categories. This database is organized just like the WordNet hierarchy, where each concept is also called a synset (that is, synonym set). Each synset is a node in the ImageNet hierarchy. Each node has more than 500 images.
The ImageNet Large Scale Visual Recognition Challenge (ILSVRC) was founded in 2010 to improve state-of-the-art technology for object detection and image classification on a large scale:

Following this overview of ImageNet, we will now take a look at various CNN model architectures.
In 2010, a challenge from ImageNet (known as ILSVRC 2010) came out with a CNN architecture, LeNet 5, built by Yann Lecun. This network takes a 32 x 32 image as input, which goes to the convolution layers (C1) and then to the subsampling layer (S2). Today, the subsampling layer is replaced by a pooling layer. Then, there is another sequence of convolution layers (C3) followed by a pooling (that is, subsampling) layer (S4). Finally, there are three fully connected layers, including the OUTPUT layer at the end. This network was used for zip code recognition in post offices. Since then, every year various CNN architectures were introduced with the help of this competition:

LeNet 5 – CNN architecture from Yann Lecun's article in 1998
Therefore, we can conclude the following points: