


Introducing Spark fundamentals
Spark is a distributed data processing framework capable of analyzing large datasets. At its very core, it consists of the following:
- DataFrames: Fundamental data structures consisting of rows and columns.
- Machine Learning (ML): Spark ML provides ML algorithms for processing big data.
- Graph processing: GraphX helps to analyze relationships between objects.
- Streaming: Spark's Structured Streaming helps to process real-time data.
- Spark SQL: A SQL to Spark engine with query plans and a cost-based optimizer.
DataFrames in Spark are built on top of Resilient Distributed Datasets (RDDs), which are now treated as the assembly language of the Spark ecosystem. Spark is compatible with various programming languages – Scala, Python, R, Java, and SQL.
Spark encompasses an architecture with one driver node and multiple worker nodes. The driver and worker nodes together constitute a Spark cluster. Under the hood, these nodes are based in Java Virtual Machines (JVMs). The driver is responsible for assigning and coordinating work between the workers.

Figure 1.1 – Spark architecture – driver and workers
The worker nodes have executors running inside each of them, which host the Spark program. Each executor consists of one or more slots that act as the compute resource. Each slot can process a single unit of work at a time.
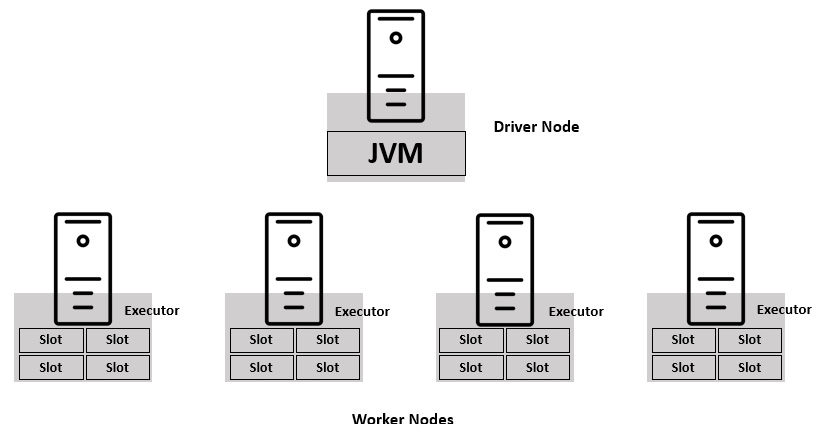
Figure 1.2 – Spark architecture – executors and slots
Every executor reserves memory for two purposes:
- Cache
- Computation
The cache section of the memory is used to store the DataFrames in a compressed format (called caching), while the compute section is utilized for data processing (aggregations, joins, and so on). For resource allocation, Spark can be used with a cluster manager that is responsible for provisioning the nodes of the cluster. Databricks has an in-built cluster manager as part of its overall offering.
Note
Executor slots are also called cores or threads.
Spark supports parallelism in two ways:
- Vertical parallelism: Scaling the number of slots in the executors
- Horizontal parallelism: Scaling the number of executors in a Spark cluster
Spark processes the data by breaking it down into chunks called partitions. These partitions are usually 128 MB blocks that are read by the executors and assigned to them by the driver. The size and the number of partitions are decided by the driver node. While writing Spark code, we come across two functionalities, transformations and actions. Transformations instruct the Spark cluster to perform changes to the DataFrame. These are further categorized into narrow transformations and wide transformations. Wide transformations lead to the shuffling of data as data requires movement across executors, whereas narrow transformations do not lead to re-partitioning across executors.
Running these transformations does not make the Spark cluster do anything. It is only when an action is called that the Spark cluster begins execution, hence the saying Spark is lazy. Before executing an action, all that Spark does is make a data processing plan. We call this plan the Directed Acyclic Graph (DAG). The DAG consists of various transformations such as read, filter, and join and is triggered by an action.
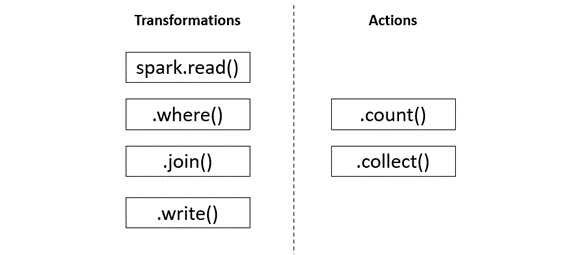
Figure 1.3 – Transformations and actions
Every time a DAG is triggered by an action, a Spark job gets created. A Spark job is further broken down into stages. The number of stages depends on the number of times a shuffle occurs. All narrow transformations occur in one stage while wide transformations lead to the formation of new stages. Each stage comprises of one or more tasks and each task processes one partition of data in the slots. For wide transformations, the stage execution time is determined by its slowest running task. This is not the case with narrow transformations.
At any moment, one or more tasks run parallelly across the cluster. Every time a Spark cluster is set up, it leads to the creation of a Spark session. This Spark session provides entry into the Spark program and is accessible with the spark keyword.
Sometimes, a few tasks process small partitions while others process larger chunks, we call this data skewing. This skewing of data should always be avoided if you hope to run efficient Spark jobs. In a broad execution, the stage is determined by its slowest task, so if a task is slow, the overall stage is slow and everything waits for that to finish. Also, whenever a wide transformation is run, the number of partitions of the data in the cluster changes to 200. This is a default setting, but can be modified using Spark configuration.
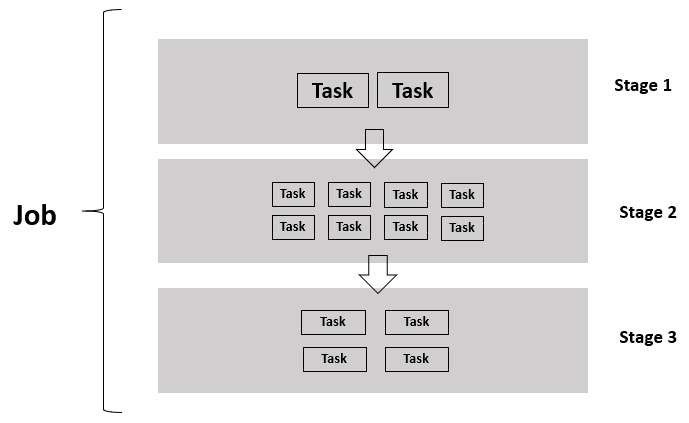
Figure 1.4 – Jobs, stages, and tasks
As a rule of thumb, the total number of partitions should always be in the multiples of the total slots in the cluster. For instance, if a cluster has 16 slots and the data has 16 partitions, then each slot receives 1 task that processes 1 partition. But instead, if there are 15 partitions, then 1 slot will remain empty. This leads to the state of cluster underutilization. In the case of 17 partitions, a job will take twice the time to complete as it will wait for that 1 extra task to finish processing.
Let's move on from Spark for now and get acquainted with Databricks.