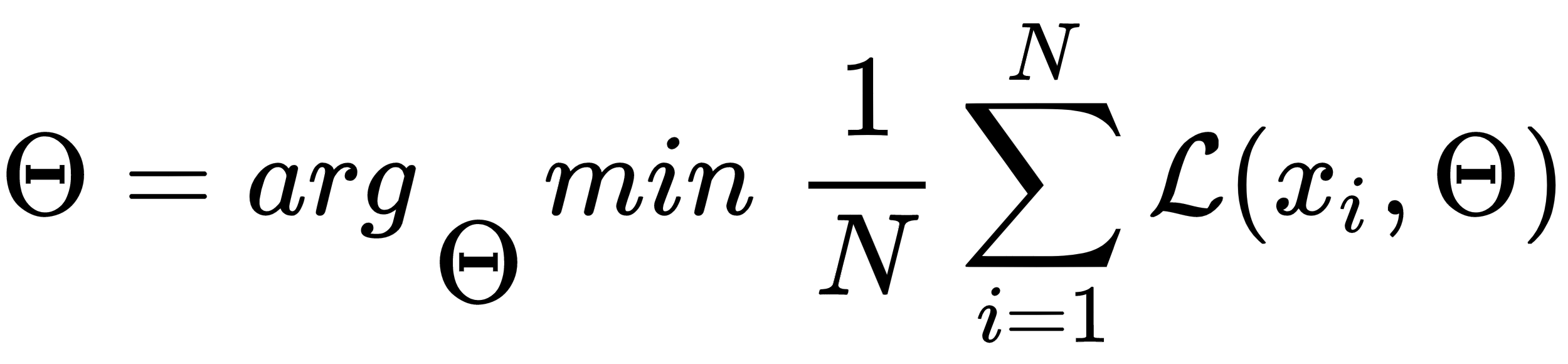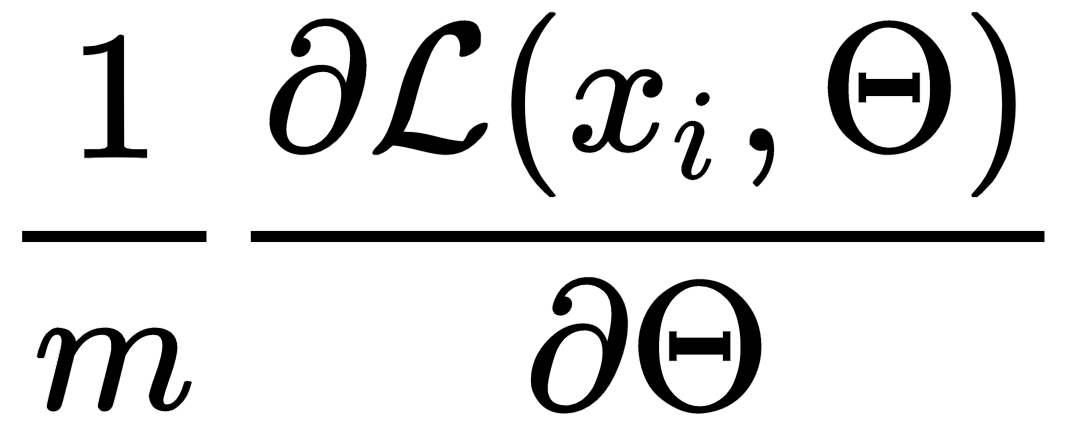In this chapter, we are discussing the convolutional neural networks (CNNs). At first we are going to discuss all components with examples in Swift just to develop an intuition about the algorithm and what is going on under the hood. However, in the real life you most likely will not develop CNN from scratch, because you will use some ready available and battle-tested deep learning framework.
So, in the second part of the chapter we will show a full development cycle of deep learning mobile application. We are going to take the photos of people's faces labeled with their emotions, train a CNN on a GPU workstation, and then integrate it into an iOS application using Keras, Vision, and Core ML frameworks.
To the end of this chapter you will have learned about:
- Affective computing
- Computer vision, its tasks, and its methods
- CNNs, their anatomy, and core concepts behind them
- Applications of CNNs in computer vision
- How to train CNNs using a GPU workstation and...