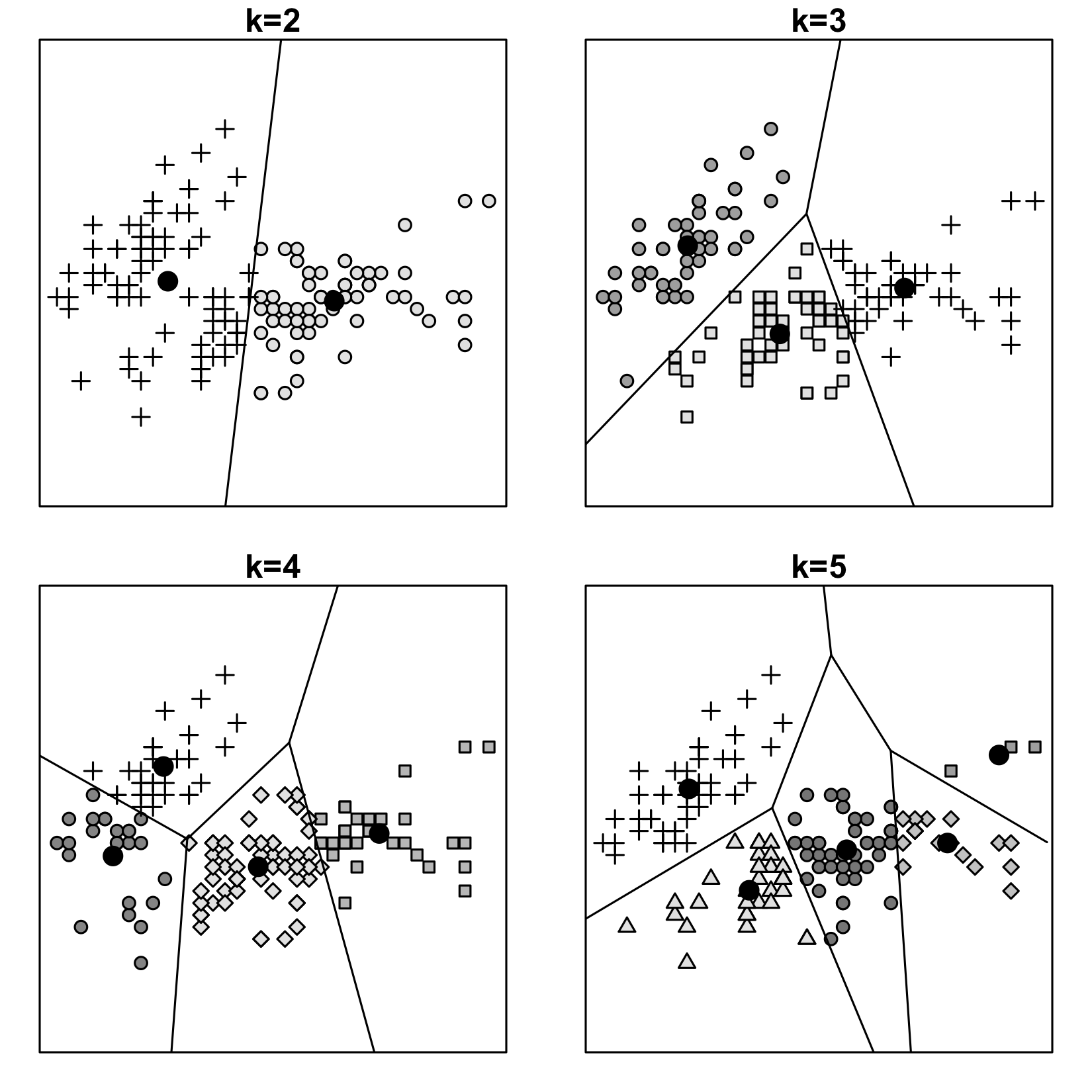
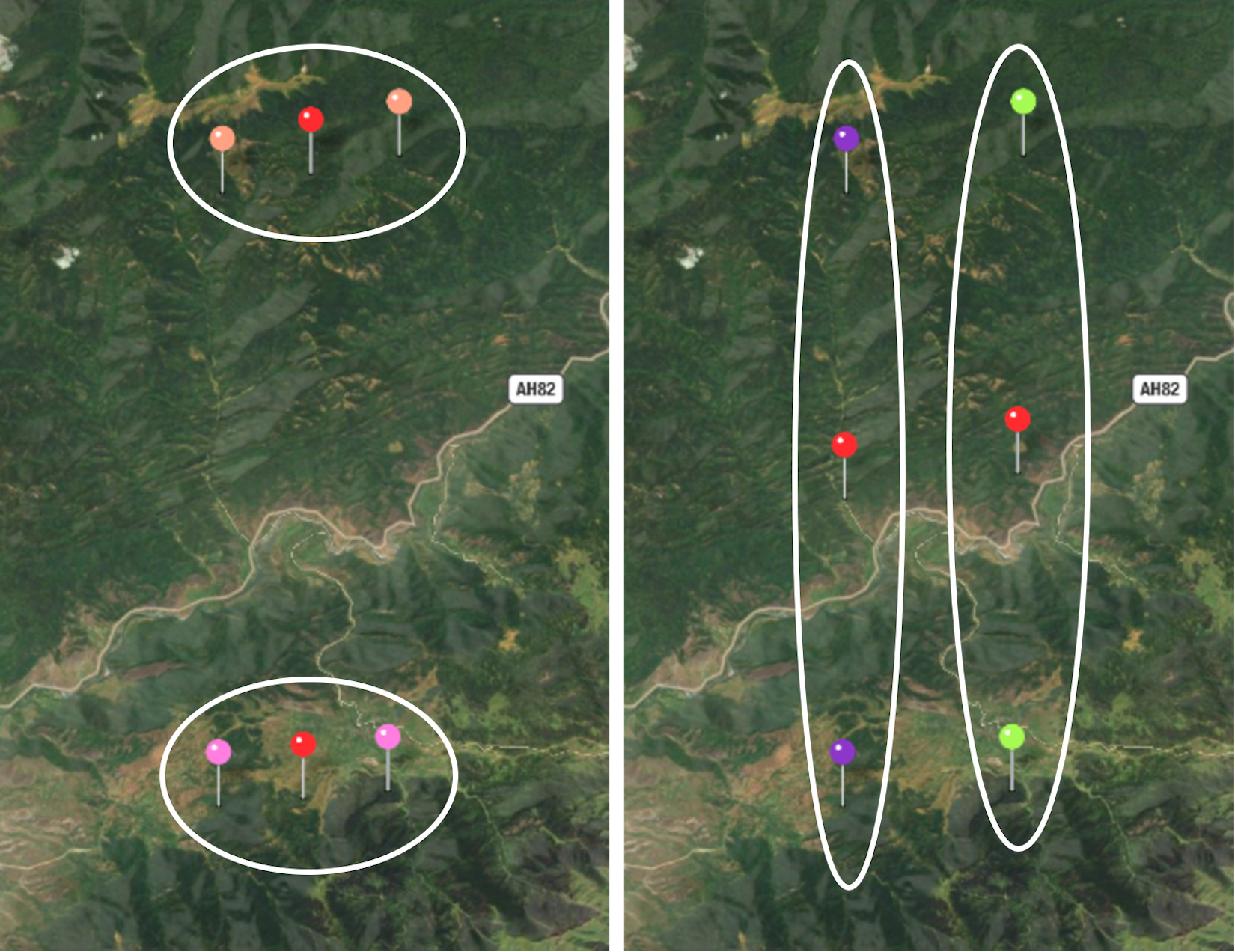
In this chapter, we're going to switch our attention from supervised learning to unsupervised learning. The algorithms that we'll discuss and implement in this chapter are k-means and k-means++ clustering.
In this chapter, we will cover the following topics:
- Instance-based algorithm of k-means clustering
- The shortcomings of the k-means and how to fix them with the k-means++
- Where you can use k-means and where you shouldn't use it
- Application of clustering for signal quantization
- How to choose the number of clusters