Chapter 8. Working with Speech Recognition and Synthesis Using Python and ROS
In this chapter, we will mainly discuss the following topics:
Introducing speech recognition, synthesis, and various speech processing frameworks
Working with speech recognition and synthesis using Python in Ubuntu/Linux, Windows and Mac OS X
Working with speech recognition and synthesis packages in ROS using Python
If the robots are able to recognize and respond the way human beings communicate, then the robot-human interaction will be much more easier and effective than any other method. However, extracting speech parameters such as meaning, pitch, duration, and intensity from human speech is a very tough task. Researchers found numerous ways to solve this problem. Now, there are some algorithms that are doing a good job in speech processing.
In this chapter, we will discuss the applications of speech recognition and synthesis in our robot and also look at some of the libraries to perform speech recognition and synthesis...
Understanding speech recognition
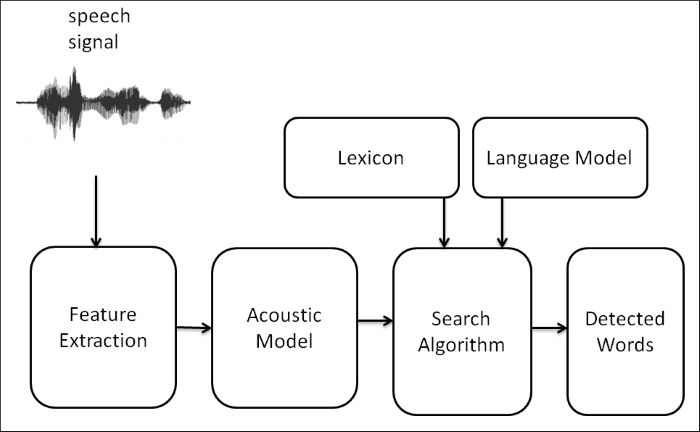
Speech recognition basically means talking to a computer and making it recognize what we are saying in real time. It converts natural spoken language to digital format that can be understood by a computer. We are mainly discussing the conversion of speech-to-text process here. Using the speech recognition system, the robot will record the sentence or word commanded by the user. The text will be passed to another program and the program will decide which action it has to execute. We can take a look at the block diagram of the speech recognition system that explains how it works.
Block diagram of a speech recognition system
The following is a block diagram of a typical speech recognition system. We can see each block and understand how a speech signal is converted to text:
The speech signal is received through a microphone and will be converted to a digital format such as PCM (Pulse Code Modulation) by the sound card inside...
Working with speech recognition and synthesis in Ubuntu 14.04.2 using Python
In this section, we will discuss Python interfacing with Pocket Sphinx, Julius, and Microsoft Speech SDK and speech synthesis frameworks such as eSpeak and Festival. Let's start with speech recognition libraries and their installation procedures.
Setting up Pocket Sphinx and its Python binding in Ubuntu 14.04.2
The following packages are required to install Pocket Sphinx and its Python bindings:
python-pocketsphinx
pocketsphinx-hmm-wsj1
pocketsphinx-lm-wsj
The packages can be installed using the apt-get command. The following commands are used to install Pocket Sphinx and its Python interface.
Installing Pocket Sphinx in Ubuntu can be done either through source code or by package managers. Here, we will install Pocket Sphinx using the package manager:
Real-time speech recognition using Pocket Sphinx, GStreamer, and Python in Ubuntu 14.04.2
The following is the code for real-time speech recognition using GStreamer:
Speech recognition using Julius and Python in Ubuntu 14.04.2
In this section, we will see how to install the speech recognition system of Julius and how to connect it to Python. The required packages (such as Julius and audio tools) are available in Ubuntu's package manager, but we also need to download and install the Python wrapper separately. Let's start with the required components for the installation.
Installation of Julius speech recognizer and Python module
The following are the instructions to install Julius and Python binding in Ubuntu 14.04.2:
The following command will install the speech recognition system of Julius:
The following command will install padsp (the pulse audio tool). It may be necessary to run the Julius speech recognizer in Ubuntu 14.04.2:
The following command will install the OSS proxy daemon to emulate the OSS sound device and stream through the ALSA device. It will emulate the /dev/dsp device...
Working with speech recognition and synthesis in Windows using Python
In Windows, there are many tools and frameworks to perform speech recognition and synthesis. The speech recognition libraries, namely, Pocket Sphinx and Julius that we discussed will also be supported in Windows. Microsoft also provides
SAPI (Speech Application Programming Interface), a set of APIs that allows you to use speech recognition and synthesis from code. These APIs are either shipped with an operating system or with Microsoft Speech SDK.
In this section, we will demonstrate how to connect Python and Microsoft Speech SDK to perform speech recognition and synthesis. This procedure will work in Windows 8, Windows 7, 32, and 64 bit.
Installation of the Speech SDK
The following is the step-by-step procedure to install Speech SDK and the Python wrapper of Speech SDK:
Working with Speech recognition in ROS Indigo and Python
Compared to other speech recognition methods, one of the easiest and effective methods to implement real time speech recognition is Pocket Sphinx and GStreamer pipeline. We discussed Pocket Sphinx, GStreamer and its interfacing with Python previously. Next, we can see a ROS package called pocketsphinx that uses the GStreamer pocketsphinx interface to perform speech recognition. The pocketsphinx ROS package is available in the ROS repository. You will get the package information at the following link
http://wiki.ros.org/pocketsphinx
Installation of the pocketsphinx package in ROS Indigo
To install the pocketsphinx package, first switch to the catkin workspace source folder.
Download the source code of the pocketsphinx package using the following command:
Execute the catkin_make command from the catkin workspace folder to build the package
Start the speech recognizer demo using the...
Working with speech synthesis in ROS Indigo and Python
In ROS, there are some ROS packages that perform speech synthesis. Here, we will discuss one ROS package. This package uses Festival as the backend. The package name is sound_play. It has nodes and launch scripts that enable speech synthesis. We need to perform the following steps for speech synthesis:
We can install the sound_play package using the following command:
After the installation of package, we have to create a sample ROS package to interact with the sound-play node. The following is the command to create a sample package in ROS with the sound-play package as dependency:
We have to create a sound_play python client code for sending text to sound play server node. This client will send the text that needs to be converted to speech to the sound_play server node. The client will send the text to convert to speech in a Topic...
The main aim of this chapter was to discuss speech recognition and synthesis and how we can implement it on our robot. By adding speech functionalities in our robot, we can make the robot more interactive than before. We saw what are the processes involved in the speech recognition and synthesis process. We also saw the block diagram of these processes and the functions of each block. After discussing the blocks, we saw some interesting speech recognition frameworks (such as Sphinx/Pocket Sphinx, Julius, and Windows Speech SDK and synthesis libraries such as eSpeak and Festival). After discussing these libraries, we discussed and worked with the Python interfacing of each library. Towards the end of this chapter, we discussed and worked with the ROS packages that perform speech recognition and synthesis functionalities.