


In this section, we will provide a short overview of the Apache Spark Jobs and APIs. This provides the necessary foundation for the subsequent section on Spark 2.0 architecture.
Any Spark application spins off a single driver process (that can contain multiple jobs) on the master node that then directs executor processes (that contain multiple tasks) distributed to a number of worker nodes as noted in the following diagram:
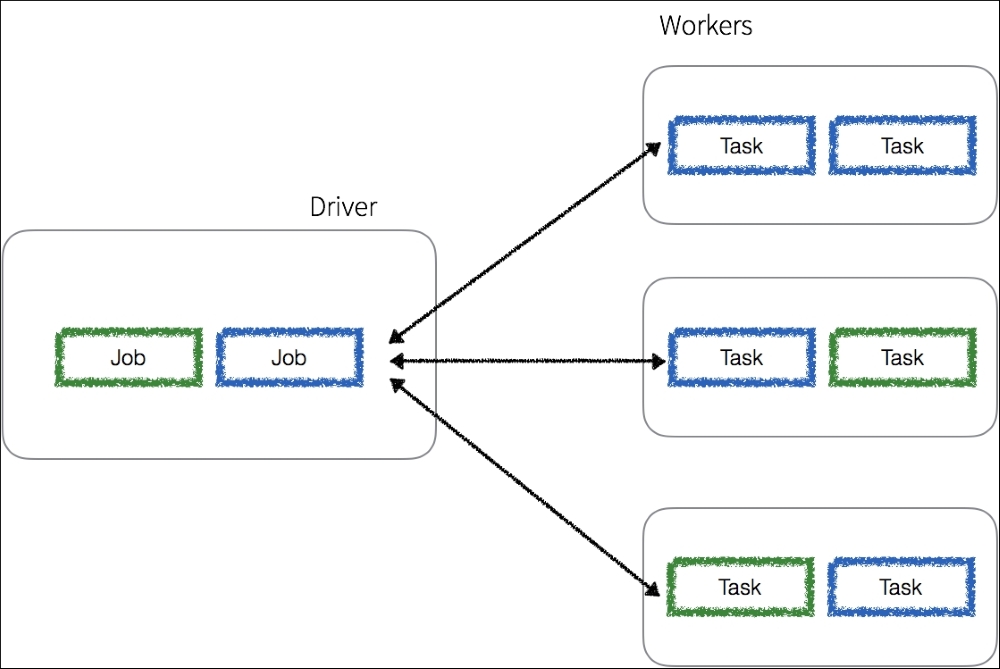
The driver process determines the number and the composition of the task processes directed to the executor nodes based on the graph generated for the given job. Note, that any worker node can execute tasks from a number of different jobs.
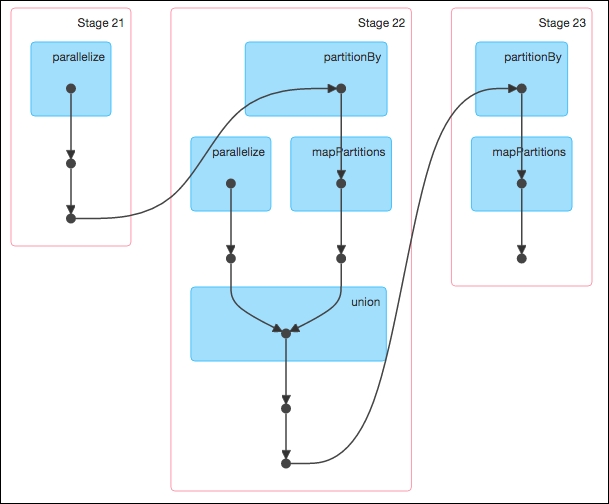
A Spark job is associated with a chain of object dependencies organized in a direct acyclic graph (DAG) such as the following example generated from the Spark UI. Given this, Spark can optimize the scheduling (for example, determine the number of tasks and workers required) and execution of these tasks:
Note
For more information on the DAG scheduler, please refer to http://bit.ly/29WTiK8.
Apache Spark is built around a distributed collection of immutable Java Virtual Machine (JVM) objects called Resilient Distributed Datasets (RDDs for short). As we are working with Python, it is important to note that the Python data is stored within these JVM objects. More of this will be discussed in the subsequent chapters on RDDs and DataFrames. These objects allow any job to perform calculations very quickly. RDDs are calculated against, cached, and stored in-memory: a scheme that results in orders of magnitude faster computations compared to other traditional distributed frameworks like Apache Hadoop.
At the same time, RDDs expose some coarse-grained transformations (such as map(...), reduce(...), and filter(...) which we will cover in greater detail in Chapter 2, Resilient Distributed Datasets), keeping the flexibility and extensibility of the Hadoop platform to perform a wide variety of calculations. RDDs apply and log transformations to the data in parallel, resulting in both increased speed and fault-tolerance. By registering the transformations, RDDs provide data lineage - a form of an ancestry tree for each intermediate step in the form of a graph. This, in effect, guards the RDDs against data loss - if a partition of an RDD is lost it still has enough information to recreate that partition instead of simply depending on replication.
Note
If you want to learn more about data lineage check this link http://ibm.co/2ao9B1t .
RDDs have two sets of parallel operations: transformations (which return pointers to new RDDs) and actions (which return values to the driver after running a computation); we will cover these in greater detail in later chapters.
Note
For the latest list of transformations and actions, please refer to the Spark Programming Guide at http://spark.apache.org/docs/latest/programming-guide.html#rdd-operations.
RDD transformation operations are lazy in a sense that they do not compute their results immediately. The transformations are only computed when an action is executed and the results need to be returned to the driver. This delayed execution results in more fine-tuned queries: Queries that are optimized for performance. This optimization starts with Apache Spark's DAGScheduler – the stage oriented scheduler that transforms using stages as seen in the preceding screenshot. By having separate RDD transformations and actions, the DAGScheduler can perform optimizations in the query including being able to avoid shuffling, the data (the most resource intensive task).
For more information on the DAGScheduler and optimizations (specifically around narrow or wide dependencies), a great reference is the Narrow vs. Wide Transformations section in High Performance Spark in Chapter 5, Effective Transformations (https://smile.amazon.com/High-Performance-Spark-Practices-Optimizing/dp/1491943203).
DataFrames, like RDDs, are immutable collections of data distributed among the nodes in a cluster. However, unlike RDDs, in DataFrames data is organized into named columns.
DataFrames were designed to make large data sets processing even easier. They allow developers to formalize the structure of the data, allowing higher-level abstraction; in that sense DataFrames resemble tables from the relational database world. DataFrames provide a domain specific language API to manipulate the distributed data and make Spark accessible to a wider audience, beyond specialized data engineers.
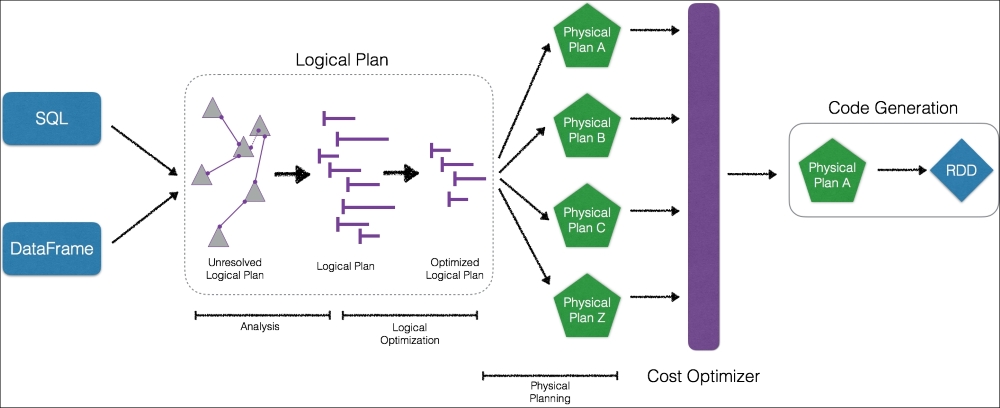
One of the major benefits of DataFrames is that the Spark engine initially builds a logical execution plan and executes generated code based on a physical plan determined by a cost optimizer. Unlike RDDs that can be significantly slower on Python compared with Java or Scala, the introduction of DataFrames has brought performance parity across all the languages.
Introduced in Spark 1.6, the goal of Spark Datasets is to provide an API that allows users to easily express transformations on domain objects, while also providing the performance and benefits of the robust Spark SQL execution engine. Unfortunately, at the time of writing this book Datasets are only available in Scala or Java. When they are available in PySpark we will cover them in future editions.
Spark SQL is one of the most technically involved components of Apache Spark as it powers both SQL queries and the DataFrame API. At the core of Spark SQL is the Catalyst Optimizer. The optimizer is based on functional programming constructs and was designed with two purposes in mind: To ease the addition of new optimization techniques and features to Spark SQL and to allow external developers to extend the optimizer (for example, adding data source specific rules, support for new data types, and so on):
Note
For more information, check out Deep Dive into Spark SQL's Catalyst Optimizer (http://bit.ly/271I7Dk) and Apache Spark DataFrames: Simple and Fast Analysis of Structured Data (http://bit.ly/29QbcOV)
Tungsten is the codename for an umbrella project of Apache Spark's execution engine. The project focuses on improving the Spark algorithms so they use memory and CPU more efficiently, pushing the performance of modern hardware closer to its limits.
The efforts of this project focus, among others, on:
Managing memory explicitly so the overhead of JVM's object model and garbage collection are eliminated
Designing algorithms and data structures that exploit the memory hierarchy
Generating code in runtime so the applications can exploit modern compliers and optimize for CPUs
Eliminating virtual function dispatches so that multiple CPU calls are reduced
Utilizing low-level programming (for example, loading immediate data to CPU registers) speed up the memory access and optimizing Spark's engine to efficiently compile and execute simple loops
Note
For more information, please refer to
Project Tungsten: Bringing Apache Spark Closer to Bare Metal (https://databricks.com/blog/2015/04/28/project-tungsten-bringing-spark-closer-to-bare-metal.html)
Deep Dive into Project Tungsten: Bringing Spark Closer to Bare Metal [SSE 2015 Video and Slides] (https://spark-summit.org/2015/events/deep-dive-into-project-tungsten-bringing-spark-closer-to-bare-metal/) and
Apache Spark as a Compiler: Joining a Billion Rows per Second on a Laptop (https://databricks.com/blog/2016/05/23/apache-spark-as-a-compiler-joining-a-billion-rows-per-second-on-a-laptop.html)