


Exploring computation management
In this section, we will briefly describe how to manage Azure Databricks clusters, the computational backbone of all of our operations. We will describe how to display information on clusters, as well as how to edit, start, terminate, delete, and monitor logs.
Displaying clusters
To display the clusters in your workspace, click the clusters icon in the sidebar. You will see the Cluster page, which displays clusters in two tabs: All-Purpose Clusters and Job Clusters:
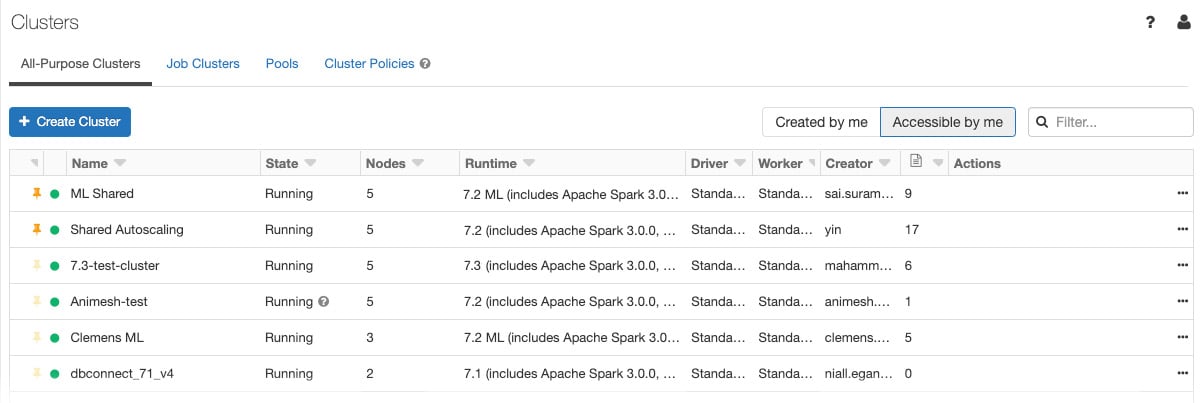
Figure 1.32 – Cluster details
On top of the common cluster information, All-Purpose Clusters displays information on the number of notebooks attached to them.
Actions such as terminate, restart, clone, permissions, and delete actions can be accessed at the far right of an all-purpose cluster:
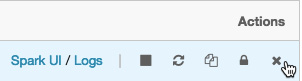
Figure 1.33 – Actions on clusters
Cluster actions allow us to quickly operate in our clusters directly from our notebooks.
Starting a cluster
Apart from creating a new cluster, you can also start a previously terminated cluster. This lets you recreate a previously terminated cluster with its original configuration. Clusters can be started from the Cluster list, on the cluster detail page of the notebook in the cluster icon attached dropdown:
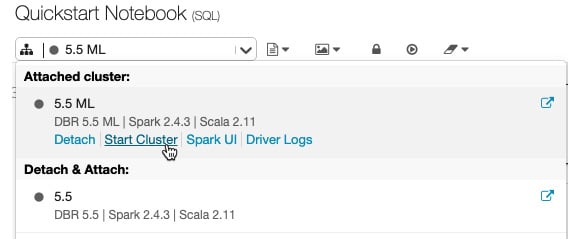
Figure 1.34 – Starting a cluster from the notebook toolbar
You also have the option of using the API to programmatically start a cluster.
Each cluster is uniquely identified and when you start a terminated cluster, Azure Databricks automatically installs libraries and reattaches notebooks to it.
Terminating a cluster
To save resources, you can terminate a cluster. The configuration of a terminated cluster is stored so that it can be reused later on.
Clusters can be terminated manually or automatically following a specified period of inactivity:
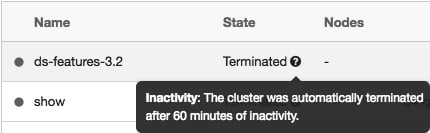
Figure 1.35 – A terminated cluster
It's good to bear in mind that inactive clusters will be terminated automatically.
Deleting a cluster
Deleting a cluster terminates the cluster and removes its configuration. Use this carefully because this action cannot be undone.
To delete a cluster, click the delete icon in the cluster actions on the Job Clusters or All-Purpose Clusters tab:

Figure 1.36 – Deleting a cluster from the Job Clusters tab
You can also invoke the permanent delete API endpoint to programmatically delete a cluster.
Cluster information
Detailed information on Spark jobs is displayed in the Spark UI, which can be accessed from the cluster list or the cluster details page. The Spark UI displays the cluster history for both active and terminated clusters:
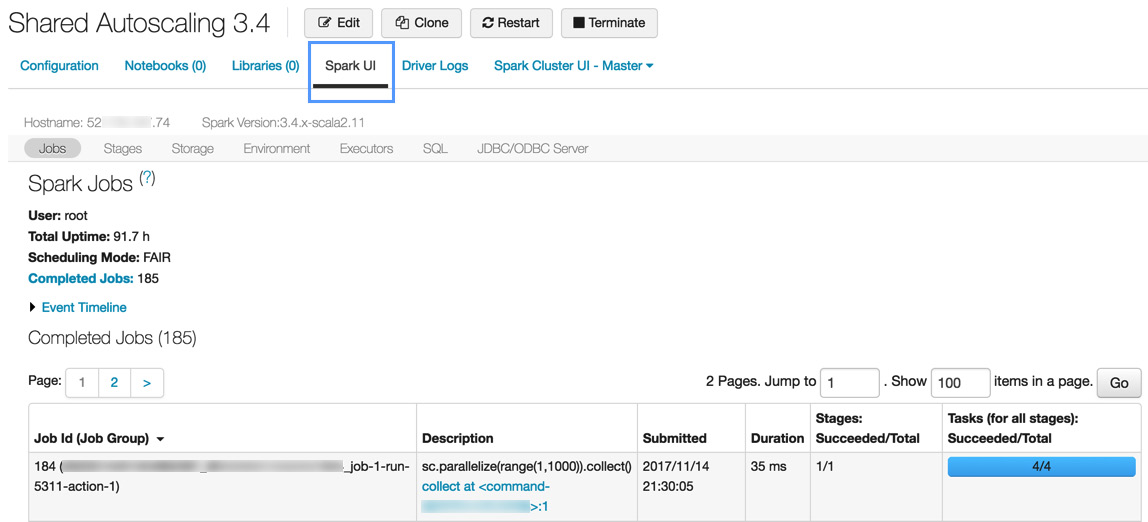
Figure 1.37 – Cluster information
Cluster information allows us to have an insight into the progress of our process and identify any possible bottlenecks that could point us to possible optimization opportunities.
Cluster logs
Azure Databricks provides three kinds of logging of cluster-related activity:
- Cluster event logs for life cycle events, such as creation, termination, or configuration edits
- Apache Spark driver and worker logs, which are generally used for debugging
- Cluster init script logs, valuable for debugging init scripts
Azure Databricks provides cluster event logs with information on life cycle events that are manually or automatically triggered, such as creation and configuration edits. There are also logs for Apache Spark drivers and workers, as well cluster init script logs.
Events are stored for 60 days, which is comparable to other data retention times in Azure Databricks.
To view a cluster event log, click on the Cluster button at the sidebar, click on the cluster name, and then finally click on the Event Log tab:
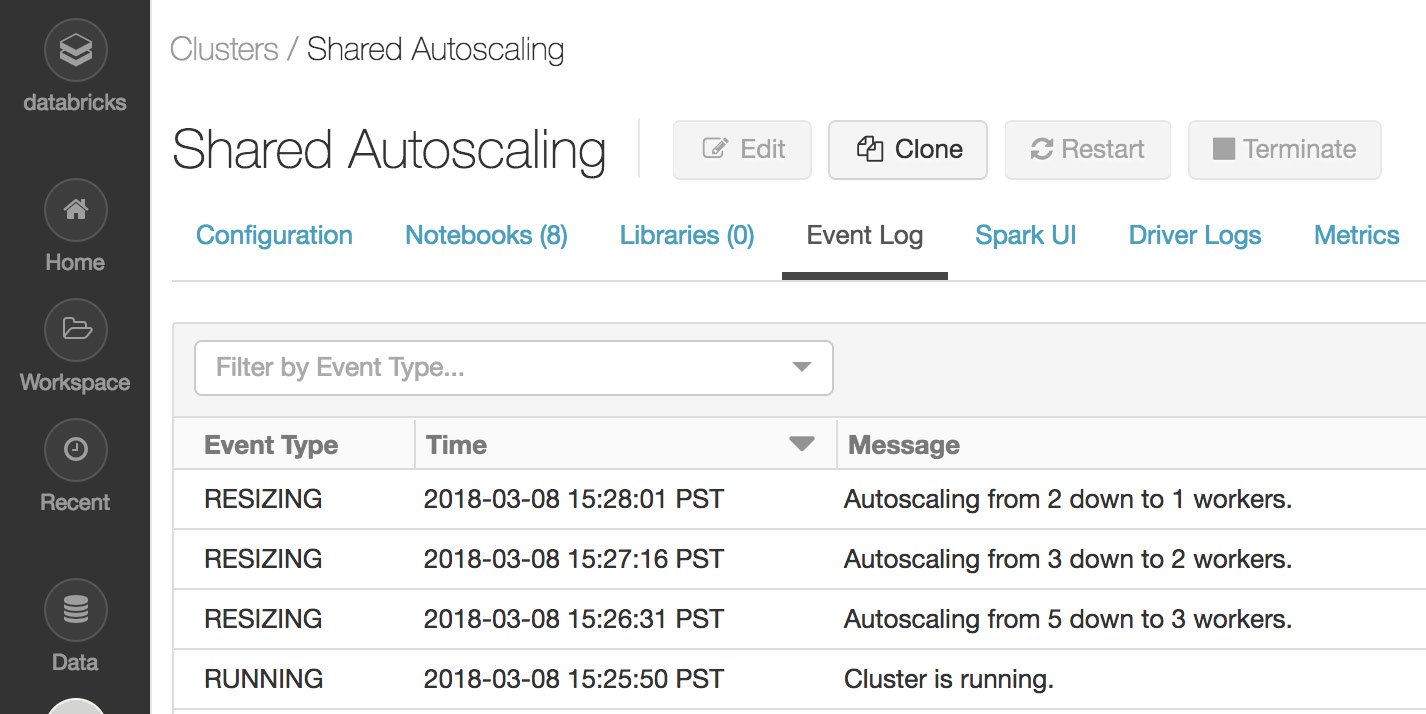
Figure 1.38 – Cluster event logs
Cluster events provide us with specific information on the actions that were taken on the cluster during the execution of our jobs.