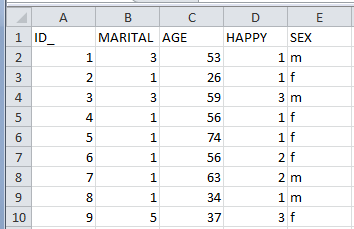
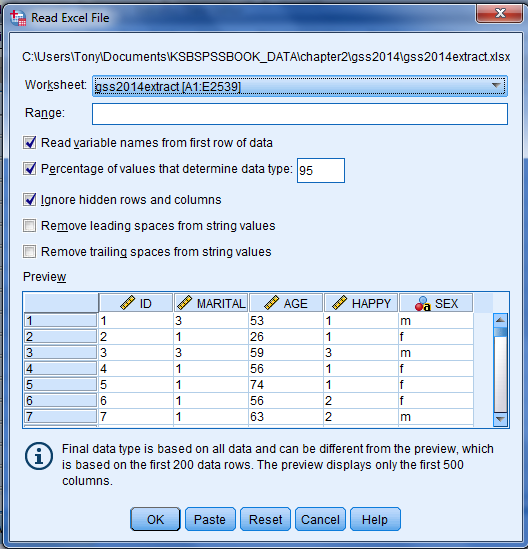
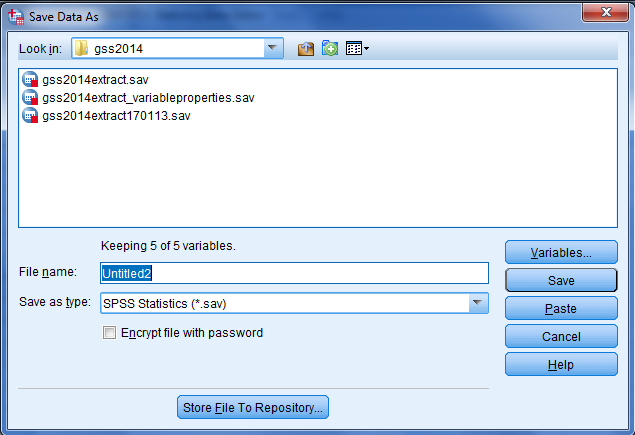
This chapter shows you how to read common file formats such as an Excel sheet or a delimited text file to IBM SPSS Statistics. The rationale for showing the reading of these formats is that most software programs read these file formats. In addition, many analysts use Excel for simple data activities such as data handling and producing charts. However, beyond these simple activities, Excel is limited in the data analytic capabilities it provides, so researchers have turned to IBM SPSS Statistics for its extensive statistical and analytical capabilities.
In order to use IBM SPSS Statistics, you must first read your data to the IBM SPSS Statistics Data Editor window. Once you successfully read the data, you provide variable properties to enrich the description of the data. After you have established the variable properties for the variables in your...