


Reading and writing data from and to Azure Cosmos DB
Azure Cosmos DB is Microsoft's globally distributed multi-model database service. Azure Cosmos DB enables you to manage your data scattered around different data centers across the world and also provides a mechanism to scale data distribution patterns and computational resources. It supports multiple data models, which means it can be used for storing documents and relational, key-value, and graph models. It is more or less a NoSQL database as it doesn't have any schema. Azure Cosmos DB provides APIs for the following data models, and their software development kits (SDKs) are available in multiple languages:
- SQL API
- MongoDB API
- Cassandra API
- Graph (Gremlin) API
- Table API
The Cosmos DB Spark connector is used for accessing Azure Cosmos DB. It is used for batch and streaming data processing and as a serving layer for the required data. It supports both the Scala and Python languages. The Cosmos DB Spark connector supports the core (SQL) API of Azure Cosmos DB.
This recipe explains how to read and write data to and from Azure Cosmos DB using Azure Databricks.
Getting ready
You will need to ensure you have the following items before starting to work on this recipe:
- An Azure Databricks workspace. Refer to Chapter 1, Creating an Azure Databricks Service, to create an Azure Databricks workspace.
- Download the Cosmos DB Spark connector.
- An Azure Cosmos DB account.
You can follow the steps mentioned in the following link to create Azure Cosmos DB account from Azure Portal.
Once the Azure Cosmos DB account is created create a database with name Sales and container with name Customer and use the Partition key as /C_MKTSEGMENT while creating the new container as shown in the following screenshot.
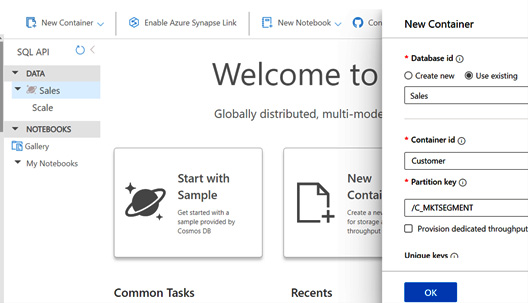
Figure 2.17 – Adding New Container in Cosmos DB Account in Sales Database
You can follow the steps by running the steps in the 2_6.Reading and Writing Data from and to Azure Cosmos DB.ipynb notebook in your local cloned repository in the Chapter02 folder.
Upload the csvFiles folder in the Chapter02/Customer folder to the ADLS Gen2 account in the rawdata file system.
Note
At the time of writing this recipe Cosmos DB connector for Spark 3.0 is not available.
You can download the latest Cosmos DB Spark uber-jar file from following link. Latest one at the time of writing this recipe was 3.6.14.
https://search.maven.org/artifact/com.microsoft.azure/azure-cosmosdb-spark_2.4.0_2.11/3.6.14/jar
If you want to work with 3.6.14 version then you can download the jar file from following GitHub URL as well.
You need to get the Endpoint and MasterKey for the Azure Cosmos DB which will be used to authenticate to Azure Cosmos DB account from Azure Databricks. To get the Endpoint and MasterKey, go to Azure Cosmos DB account and click on Keys under the Settings section and copy the values for URI and PRIMARY KEY under Read-write Keys tab.
How to do it…
Let's get started with this section.
- Create a new Spark Cluster and ensure you are choosing the configuration that is supported by the Spark Cosmos connector. Choosing low or higher version will give errors while reading data from Azure Cosmos DB hence select the right configuration while creating the cluster as shown in following table:

Table 2.2 – Configuration to create a new cluster
The following screenshot shows the configuration of the cluster:

Figure 2.18 – Azure Databricks cluster
- After your cluster is created, navigate to the cluster page, and select the Libraries tab. Select Install New and upload the Spark connector
jarfile to install the library. This is theuber jarfile which is mentioned in the Getting ready section:
Figure 2.19 – Cluster library installation
- You can verify that the library was installed on the Libraries tab:

Figure 2.20 – Cluster verifying library installation
- Once the library is installed, you are good to connect to Cosmos DB from the Azure Databricks notebook.
- We will use the customer data from the ADLS Gen2 storage account to write the data in Cosmos DB. Run the following code to list the
csvfiles in the storage account:display(dbutils.fs.ls("/mnt/Gen2/ Customer/csvFiles/")) - Run the following code which will read the
csvfiles from mount point into a DataFrame.customerDF = spark.read.format("csv").option("header",True).option("inferSchema", True).load("dbfs:/mnt/Gen2Source/Customer/csvFiles") - Provide the cosmos DB configuration by executing the following code.
Collectionis the Container that you have created in the Sales Database in Cosmos DB.writeConfig = ( "Endpoint" : "https://testcosmosdb.documents.azure.com:443/", "Masterkey" : "xxxxx-xxxx-xxx" "Database" : "Sales", "Collection" :"Customer", "preferredRegions" : "East US")
- Run the following code to write the
csvfiles loaded in customerDF DataFrame to Cosmos DB. We are using save mode asappend.#Writing DataFrame to Cosmos DB. If the Comos DB RU's are less then it will take quite some time to write 150K records. We are using save mode as append. customerDF.write.format("com.microsoft.azure.cosmosdb.spark") \ .options(**writeConfig)\ .mode("append")\ .save() - To overwrite the data, we must use save mode as overwrite as shown in the following code.
#Writing DataFrame to Cosmos DB. If the Comos DB RU's are less then it will take quite some time to write 150K records. We are using save mode as overwrite. customerDF.write.format("com.microsoft.azure.cosmosdb.spark") \ .options(**writeConfig)\ .mode("overwrite")\ .save() - Now let's read the data written to Cosmos DB. First, we need to set the
configvalues by running the following code.readConfig = { "Endpoint" : "https://testcosmosdb.documents.azure.com:443/", "Masterkey" : "xxx-xxx-xxx", "Database" : "Sales", "Collection" : "Customer", "preferredRegions" : "Central US;East US2", "SamplingRatio" : "1.0", "schema_samplesize" : "1000", "query_pagesize" : "2147483647", "query_custom" : "SELECT * FROM c where c.C_MKTSEGMENT ='AUTOMOBILE'" # } - After setting the
configvalues, run the following code to read the data from Cosmos DB. In thequery_customwe are filtering the data forAUTOMOBILEmarket segments.df_Customer = spark.read.format("com.microsoft.azure.cosmosdb.spark").options(**readConfig).load() df_Customer.count() - You can run the following code to display the contents of the DataFrame.
display(df_Customer.limit(5))
By the end of this section, you have learnt how to load and read the data into and from Cosmos DB using Azure Cosmos DB Connector for Apache Spark.
How it works…
azure-cosmosdb-spark is the official connector for Azure Cosmos DB and Apache Spark. This connector allows you to easily read to and write from Azure Cosmos DB via Apache Spark DataFrames in Python and Scala. It also allows you to easily create a lambda architecture for batch processing, stream processing, and a serving layer while being globally replicated and minimizing the latency involved in working with big data.
Azure Cosmos DB Connector is a client library that allows Azure Cosmos DB to act as an input source or output sink for Spark jobs. Fast connectivity between Apache Spark and Azure Cosmos DB provides the ability to process data in a performant way. Data can be quickly persisted and retrieved using Azure Cosmos DB with the Spark to Cosmos DB connector. This also helps to solve scenarios, including blazing fast Internet of Things (IoT) scenarios, and while performing analytics, push-down predicate filtering, and advanced analytics.
We can use query_pagesize as a parameter to control number of documents that each query page should hold. Larger the value for query_pagesize, lesser is the network roundtrip which is required to fetch the data and thus leading to better throughput.