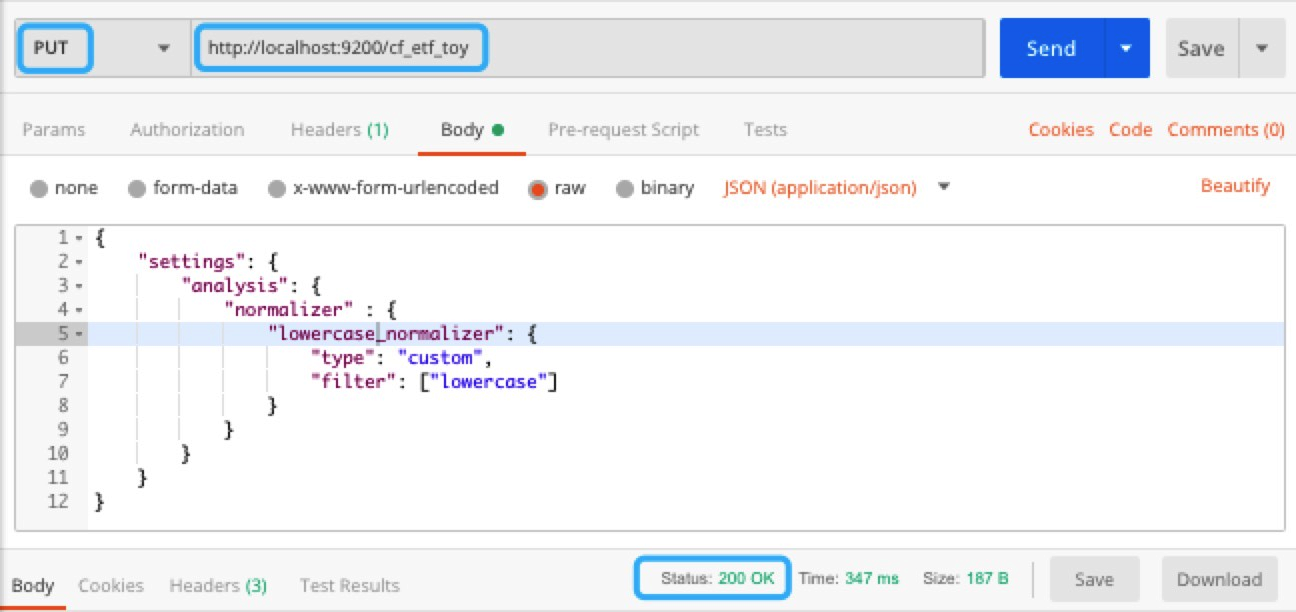
In Chapter 4, Mapping APIs, we learned about the mapping API; we also mentioned that the analyzer is one of the mapping parameters. In Chapter 1, Overview of Elasticsearch 7, we introduced analyzers and gave an example of a standard analyzer. The building blocks of an analyzer are character filters, tokenizers, and token filters. They efficiently and accurately search for targets and relevant scores, and you must understand the true meaning of the data and how a well-suited analyzer must be used. In this chapter, we will drill down to the anatomy of the analyzer and demonstrate the use of different analyzers in depth. During an index operation, the contents of a document are processed by an analyzer and the generated tokens are used to build the inverted index. During a search operation, the query content is processed by a search analyzer to generate tokens...
 Argentina
Argentina
 Australia
Australia
 Austria
Austria
 Belgium
Belgium
 Brazil
Brazil
 Bulgaria
Bulgaria
 Canada
Canada
 Chile
Chile
 Colombia
Colombia
 Cyprus
Cyprus
 Czechia
Czechia
 Denmark
Denmark
 Ecuador
Ecuador
 Egypt
Egypt
 Estonia
Estonia
 Finland
Finland
 France
France
 Germany
Germany
 Great Britain
Great Britain
 Greece
Greece
 Hungary
Hungary
 India
India
 Indonesia
Indonesia
 Ireland
Ireland
 Italy
Italy
 Japan
Japan
 Latvia
Latvia
 Lithuania
Lithuania
 Luxembourg
Luxembourg
 Malaysia
Malaysia
 Malta
Malta
 Mexico
Mexico
 Netherlands
Netherlands
 New Zealand
New Zealand
 Norway
Norway
 Philippines
Philippines
 Poland
Poland
 Portugal
Portugal
 Romania
Romania
 Russia
Russia
 Singapore
Singapore
 Slovakia
Slovakia
 Slovenia
Slovenia
 South Africa
South Africa
 South Korea
South Korea
 Spain
Spain
 Sweden
Sweden
 Switzerland
Switzerland
 Taiwan
Taiwan
 Thailand
Thailand
 Turkey
Turkey
 Ukraine
Ukraine
 United States
United States